
前回の記事に引き続き、今回も仮想通貨botの開発状況をまとめていきます。
今回は書籍「数字のセンスを磨く データの読み方・活かし方」を読んで、学んだことや考えたことをまとめました。
マインドマップを書いたのは久しぶり。それくらいこの本は良かった。 pic.twitter.com/tKVMbxA0A1
— よだか(夜鷹/yodaka) (@yodakablog) October 6, 2024

データ分析を学ぶ基礎固めとして大変有益な本でした。
解決したかったこと
・データ分析の基礎固めをする
・データの扱い方についての体系的な知識を手に入れる
・今後、MLの学習と実装を進めるにあたって行う無駄な学習を減らす
概要
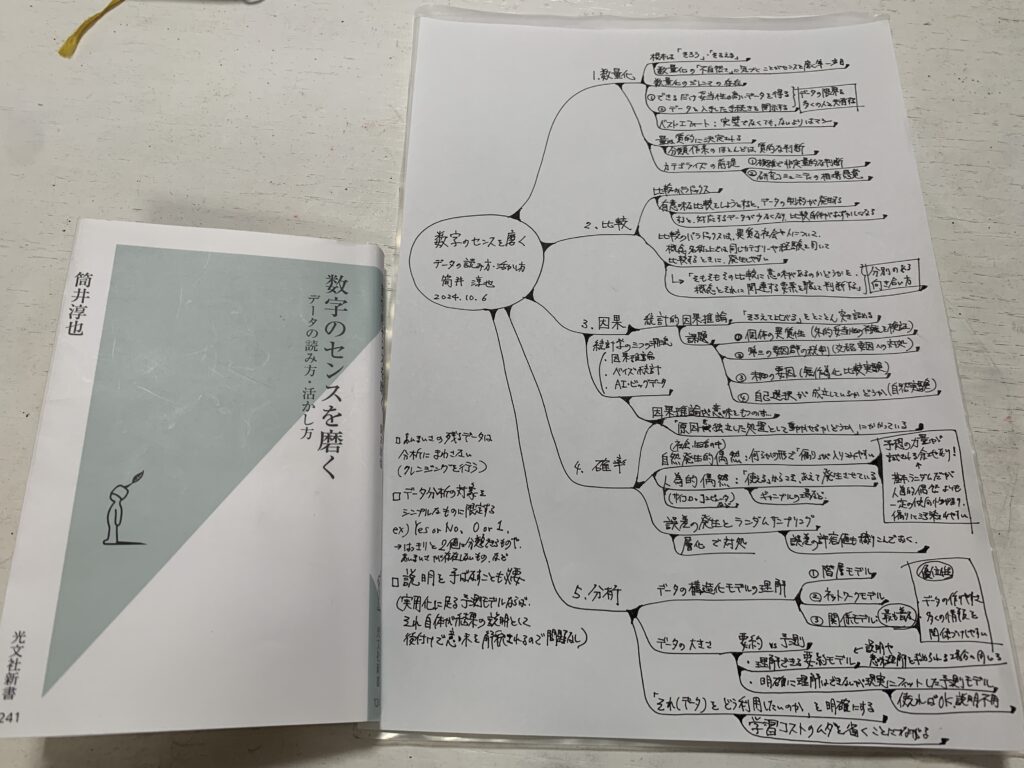
「数字を見る」とはどういうことなのかを根本的に考え直すきっかけを与えてくれる本。
数字に向き合うために必要な知識体系や概念から丁寧に説明し、分析手法の基礎を深く理解することができる。
特に、「因果のセンス」の章で、現在主流となっている考え方が大きな潮流の中でどのように位置付けられているのかということに言及している部分は、物事を体系的に理解するために大切なことを感じさせてくれる。
文系出身の私には、本書のように文字情報が多めの媒体は非常に相性が良いので、今後も技術書だけに偏らないように定期的に本書のような媒体で知識をアップデートしていく。
数量化のセンス
数量化の基本は「そろう・そろえる」ことにある。その不自然さに気づくことが数量化のセンスを磨く第一歩。
数量化のジレンマの存在を知る。(正確な数字を得ようとすればするほど、その数値を得られなくなる)
データの限界を多くの人と共有する。
①できる限り妥当性の高いデータを得る
②データを入手した手続きを開示する
「完璧でなくても、ないよりマシ」という数量化のベストエフォートを頭に入れておく。
量は質的に決定される。分析作業のほとんどは、質的な判断である。カテゴライズするのは人間の主観的な判断。カテゴライズの前提は①複雑で非定量的な判断と②研究コミュニティの相場感覚。
比較のセンス
比較のパラドックスの存在。有意味な比較をしようとするとデータの制約が生じる。すると、分析の目的に対応データが少なくなり、比較自体が難しくなる。
比較のパラドックスは、異質な社会や人について概念や名称の上では同じカテゴリーや経験を用いて比較するときに発生しやすい。
そのため、「そもそもその比較には意味があるのかどうか」を比較にまつわる概念とそれに関連する諸要素を考慮して判断することが重要。
データを見るときは、分別のある向き合い方が求められる。
因果のセンス
統計学には3つの潮流がある。(因果推論、ベイズ統計、AI・ビッグデータ)
この章では「統計的因果推論」の話題が中心となる。
統計的因果推論の真髄は「そろえてくらべる」をとことん突き詰めることにある。
統計的因果推論の主な課題は4つ。
①個体の異質性(外的妥当性の有無を検証)
②第三の要因群の統制(交絡要因への対処)
③未知の要因(無作為化比較実験)
④自己選択が成立しているかどうか(自然実験による観測)
この中で最も厄介なものが④自己選択の問題。
因果推論が意味を持つのは、「原因を独立した処置として動かせるかどうか」にかかっている。
確率のセンス
bot作りにおいては、この章は特に示唆に富んでいます。
世の中の事象は確率で定義できる。偶然発生した出来事も確率を算定することができる。
偶然には「自然発生的偶然」と「人為的偶然」がある。
自然発生的偶然は、社会・生活の中で発生する偶然。何らかのかたちで「偏り」が入り込みやすい。基本ランダムだが、人為的偶然よりも一定の傾向性があり、偏りに汚染されやすい。そのため、予測の力量が試される余地がある。
人為的偶然は、サイコロやコンピュータなど人間が意図的に生み出した偶然。何らかの目的に「使える」からこそ、あえて発生させている。(たとえばギャンブルなど)
誤差の発生とランダムサンプリング。誤差の発生には層化で対処する。また、誤差の許容値も織り込んでおく。
分析のセンス
まずはデータが構造化されたものかそうでないものかを区別する。(構造化データor非構造化データ)
データの構造化モデルの理解が分析の土台。
データ構造には3種類ある。(階層モデル、ネットワークモデル、関係モデル)
最も普及しているのは「関係モデル」。このモデルはデータの作りやすさや多くの情報を関係付けやすいという点で他のデータ構造モデルに対して優位性を持つ。
データの大きさについては、理解を重視する要約モデルvs実用を重視する予測モデルという構図がある。
要約モデルは説明や理解を求められる場合に用いる。
予測モデルは現実にフィットした予測を算出したい時に用いる。その際に、明確に理解はできないが現実にフィットしていればOKという前提で用いられる。
データをどうしたいのかを明確に定義することで、要約モデル、予測モデルの選択をする必要がある。これにより、学習者は無駄な学習コストを省くことができる。
宿題
- 曖昧さの残るデータは分析に回さない
→データのクレンジングを行う - データ分析の対象をシンプルなものに限定する
(1 or 0, Yes or No, 買い or 売り などはっきりと分類できるものや曖昧さが存在しないもの) - 説明を手放すことも必要だと心得る
(実用化に足る予測モデルならばそれ自体が結果の説明として後付けで意味を解釈されるため、内容の説明はしなくて良い)
まとめ
今回は、MLbot開発の一環としてデータ分析を学ぶ基礎固めをしました。
参考にした書籍は「数字のセンスを磨く~データの読み方・活かし方 」です。
文系出身の私にも非常に分かりやすくまとまっていたと感じます。
今後もこの調子で開発の状況を発信していきます。