
前回の記事に引き続き、今回も仮想通貨botの開発状況をまとめていきます。
今回は「機械学習の基本〜教師なし学習〜」をテーマに学んだことをまとめます。
参考にしたのは、90分で覚える!Pythonによる機械学習の基本〜教師なし学習編〜【Pythonデータサイエンス超入門】です。
概要を掴むための勉強。詳細な部分には拘らず、とりあえずコード書きながら理解していきます。
90分で覚える!Pythonによる機械学習の基本〜教師なし学習編〜【Pythonデータサイエンス超入門】 https://t.co/KwnXMM1T8J @YouTubeより
— よだか(夜鷹/yodaka) (@yodakablog) January 12, 2024
機械学習とは
機械学習とは、大量のデータからパターンやルールを見つけ出し、人間の「学習」に相当する仕組みを実現する方法。「教師あり学習」「教師なし学習」「強化学習」の3種類がある。
①教師あり学習:ラベル付きデータを与える。ラベルごとの特徴を調べたり予測したりする。犬とか猫とか像とかのデータを与えてパターン認識をさせる。 →自社製品購入者のデータを与えて、特徴や傾向を分析する。
②教師なし学習:ラベルのないデータを与えて、グループ分けや関連性を調査。動物の写真をランダムに与えて似たもの同士でグループ分けをさせる。→顧客リストの属性・購入履歴データを元に購買傾向の近い顧客のグループ分け。同時に発生する事象を調べる。→価格変化の関連性を調べるのに役立ちそう。
③強化学習:「報酬」の定義を教えて、自ら学ばせる。AIを活用する領域。試行回数の最大化が重要。ルンバの掃除動線の自動学習や対戦ゲーム手法の最適化など。

今回学んだのは2番目の「教師なし学習」ですね。
【次元削減】
情報を残したままデータ削減をする。2次元表示から1次元表示にする。要素が多い時ほど重宝する。 実際には、5次元表示のものを2次元表示にする時などに使う。 要するに、高次元のものをなるべく情報を削ぎ落とさないように低次元に落とし込む方法のこと。
大量のデータ(変数が多いデータ)を視覚的に表したい時に使う手法。 大まかに分析したい時はPCA,SVD。 詳細に分析したいときはt-SNE,UMAP。
【PCA/SVD】
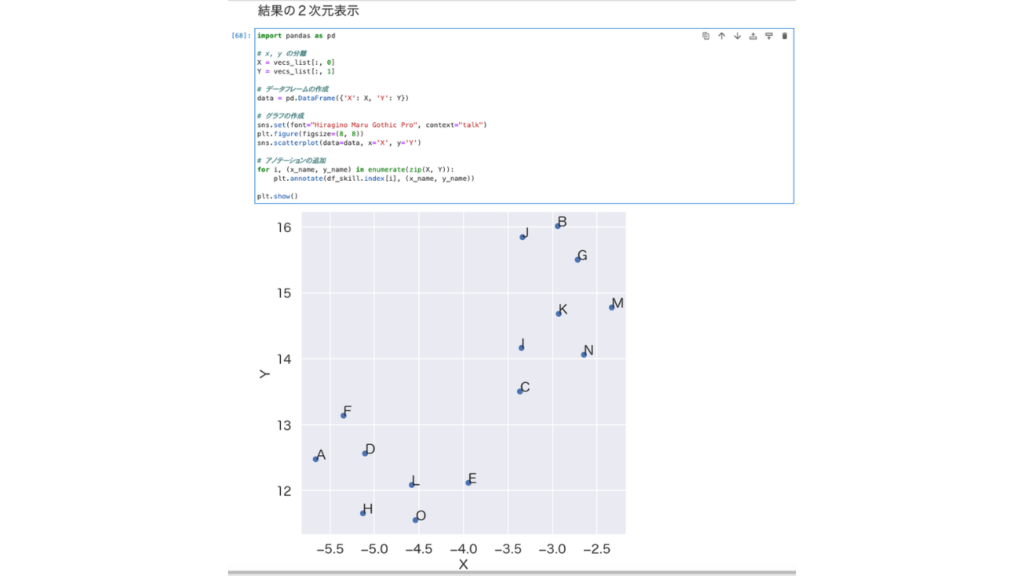
結果を2次元表示した際、Y軸の意味の考察ができる。どんな傾向が見られるのかを掴むことができるため、解釈の補助がしやすい。
【寄与率】 低次元に落とした時に、情報がどれだけ残っているかを示す。(PCA/SVDのみ)
記載されているコードでエラーが出たので、ChatGPTで修正しました。
【コード修正】
→二次元表示する際にsns.scatterplot()に関するエラーが出たので、ChatGPTで書き直し。無事、稼働した。なんとなく動いたのでひとまずOK.
【宿題】
エラーの内容については、今後必要があれば掘り下げる。 pic.twitter.com/6kxarr4ZX9— よだか(夜鷹/yodaka) (@yodakablog) January 12, 2024
import pandas as pd
# x, y の分離
X = vecs_list[:, 0]
Y = vecs_list[:, 1]
# データフレームの作成
data = pd.DataFrame({'X': X, 'Y': Y})
# グラフの作成
sns.set(font="Hiragino Maru Gothic Pro", context="talk")
plt.figure(figsize=(8, 8))
sns.scatterplot(data=data, x='X', y='Y')
# アノテーションの追加
for i, (x_name, y_name) in enumerate(zip(X, Y)):
plt.annotate(df_skill.index[i], (x_name, y_n
ame))
plt.show()
【宿題】
エラーの内容については、今後必要があれば掘り下げる。
【t-SNE/UMAP】
データの密集具合を調整して見やすくするのがポイント。(perplexity)どういうグループになっているのかを理解したい時に役立つ。 精度は高いが解釈が複雑になる。 UMAPnoを使う前に「!pip install umap-learn 」でインストール。 UMAPはimportさえ終わればt-SNEよりも早い傾向にある。
pip install umap-learn
【クラスタリング】
クラスタリングとは「データをにたもの同士で自動でグループ分けする」技術。データが何次元もある時に使う。階層クラスタリング(個別の詳細まで分析)と非階層クラスタリング(グループ分けにとどまる)がある。非階層クラスタリングの方がよく使われる。
①K-means(K-平均法)
クラスタリング結果の確認はクラスタリング×次元削減で実行する。K-means(K-平均法)が土台。個々のデータの傾向が一目で分かりやすく示される。クラスタ数は人間が指定する必要がある。クラスタ数を増やすと、判断基準が増える。適切なクラスタ数はエルボー法で求められる。
【K-meansの最適なクラスタ数の推測(エルボー法)】
グループ数を変えて、傾向を一つずつ見ていく。 図で示された傾きが緩やかになったポイントに注目する →出力されるものがどんな値に左右されるのか知っておく必要がある。間違った分析をしないように注意。
→人間が解釈して説明できるようにする必要がある。「解釈面」「技術面」の両面からみて最終的にクラスタ数を決定する。
②X-means:クラスタの自動生成
上記の過程を自動化して実行。各種実行プロセスを理解していることが前提。 →この点は必要になったらまた学び直す。
この部分は今は深く理解する必要がないと判断しました。
【アソシエーション分析】
同時に発生する事象を調べる。関係性の強さを表す指標Support(支持度),Confidence(信頼度),Lift(リフト値)。相関関係を方向性の観点から示す 元データの変換(False or Trueなど)が必要な場合がある。 →ペアトレードなどに使えそう。
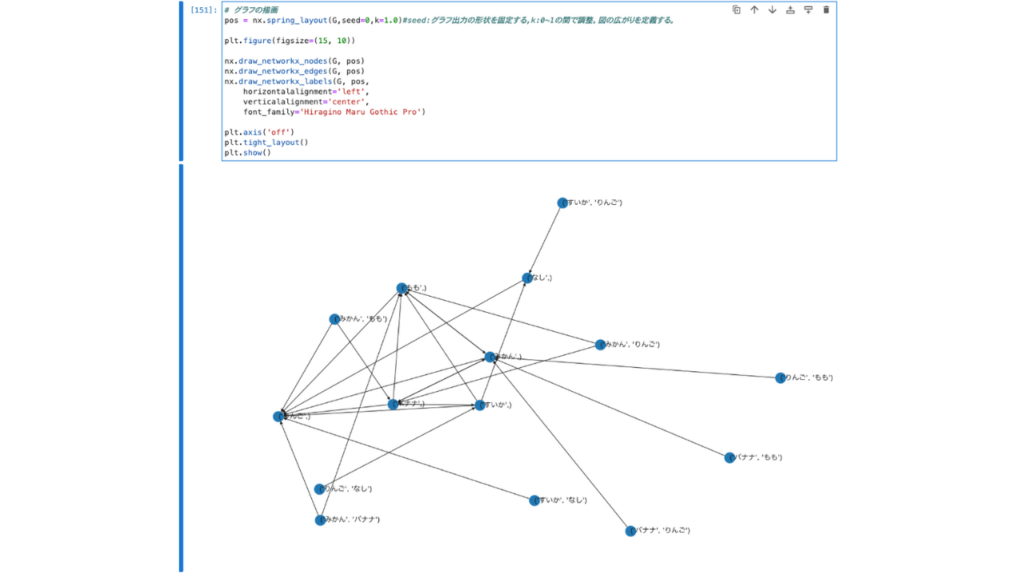
【グラフの描画】
mlxtendとnetworkxを使う。関係グラフの初期化が必要な場合もある。
【描画に関するポイント】seed:グラフ出力の形状を固定する,k:0~1の間で調整。図の広がりを定義する。
【宿題】
①トークンの取引履歴などのデータから相関関係の分析をする。
②有効な戦略を組み立てたり検証したりする
③検証プロセスが効果を上げたらプログラムで自動化する
④各種パラメータの自動調整を行うプログラムを書く
【雑感】
様々なモジュールを利用することが前提だが、ひとつひとつの機能や仕組みをしっかり理解しようとしていると時間が足りない。部分的な理解で進めらるところはどんどん進めていくと良い。
だんだんと学習内容が地に足のつかないものになっているため、実際に使えるものや使うものを学習することにシフトチェンジする必要がある。機械学習は高度な内容なので、今の段階では表面上の理解でヨシとする。
今回の学習は概要理解が目的なので、細かい部分の理解には拘らない。
pip install pyclustering
まとめ
機械学習の中でも「教師なし学習」の定義とそれをPythonで実行する方法を学びました。
現時点で活かせそうなことは「宿題」にまとめたことです。
実際に必要な技術を学びながら、Botの戦略執行に組み込んでいきます。