
こんにちは、ぼっちbotterよだかです。
前回は J-Reversion を先に定義し直し、観測器 J 系統を「構造の白黒をつける層」として置き直しました。今回はその続きとして、これまで MMArbSignalEngine 側の診断系に留まっていた Lead-Lag を、J 系統の判定器として一旦形にしています。anchor の取り方、future outcome の持たせ方、YES / HOLD / NO の返し方を整理しつつ、Grafana 上で読めるところまで持っていった一方で、まだ解釈コストの高い部分も残っています。今回は、その目的と実装の要点、実際にやったこと、そして現在地をまとめます。
-

-
🛠️開発記録#481(2026/3/11)「multi_market_probe開発ログ ― J-Reversionを先に定義し直した話」
続きを見る
1. 今回の目的:Lead-LagをJ系統の判定器として置き直す
今回の目的は、Lead-Lag を「診断が出る仕組み」のままにせず、観測器 J 系統の中で意味を持つ判定器として置き直すことでした。
前回は、J-Reversion を先に定義し直しました。そこでは、J を執行判定器ではなく、構造の白黒をつけるための層として扱う方針をはっきりさせています。つまり、いまこの瞬間に注文してよいかを返すのではなく、この市場ペアにそういう構造があると見てよいのかを YES / HOLD / NO で返す装置として J を作り直した、というのが前回までの流れでした。
今回はその続きです。ただし、対象は歪み回帰ではなく Lead-Lag に移りました。
もともと multi_market_probe の中では、Lead-Lag 自体はすでにまったく手つかずだったわけではありません。MMArbSignalEngine 側で、どの市場が先に動いていて、どのくらいの時間差で追随しているのかを診断する仕組みは入っていました。best_tau、score、stability、pairs といった値を出し、LEADLAG_DIAG や SIGNAL(leadlag) を発行するところまではできていたからです。
ただ、そこで返ってくるのはあくまで「Lead-Lag っぽい関係が見えているかどうか」の診断でした。
それ自体は役に立ちますが、J 系統として見たときには少し足りません。観測器の中で本当にほしいのは、
この市場ペアに Lead-Lag 構造があると言ってよいのか
どちら向きにその構造が出ているのか
まだ保留なのか、構造なしと判断してよいのか
までを、判定として返してくれることです。
つまり今回は、Lead-Lag を「相関っぽいものを眺める材料」から、「構造白黒判定の対象」へ進めることがテーマでした。
この差は見た目以上に大きいです。
たとえば、相関スコアが高い、best_tau が出ている、signal_pass が立っている、というだけでは、それが実際に lag 側の将来変化につながっているのかは分かりません。ある時間差で関係が見えているように見えても、future outcome が弱ければ、それを構造と呼ぶのはまだ早いかもしれません。逆に、relation 側はそこまで強くなくても、一定の方向で future outcome が揃うなら、観測器としては「何かありそうだ」と読みたくなる場面もあります。
今回やりたかったのは、まさにこの部分を埋めることでした。
Lead-Lag を J 系統に置き直すということは、単にメトリクスを増やすことではありません。relation の有無を見るだけでなく、その relation が future outcome とつながっているかまで含めて、構造判定器としてまとめ直す必要があります。だから今回は、既存の Lead-Lag 診断をそのまま J に流用するのではなく、anchor をどう取るか、future outcome をどう持たせるか、そして最終的に YES / HOLD / NO をどう返すかをあらためて整理しながら進めました。
言い換えると、今回の目的は Lead-Lag を「見えるもの」にすることではなく、「読めるもの」にすることでした。
これまでの Lead-Lag は、診断としては存在していても、J 系統の中ではまだ中途半端な位置にありました。今回はそこに J-LeadLag を追加し、少なくとも観測器の側で
構造あり
まだ判定保留
構造なし
を方向別に返せるところまで持っていこうとしています。
もちろん、これはまだ執行判定ではありません。最終的にそれを実際のトレードへつなぐには、execution feasibility や hedge、コスト、板厚など、別の層の話が必要になります。ただ、そこへ進む前にまず必要なのは、「この市場ペアに Lead-Lag として読む価値があるのか」を観測器として言えるようにすることでした。
今回は、そのための J-LeadLag を一旦形にする回です。
2. 実装方針:執行判定ではなく、構造白黒判定に絞る
今回の Lead-Lag 実装で最初に決めたのは、これを執行判定まで背負わせないことでした。
やりたいのは「今すぐ注文してよいか」を返す装置ではなく、binance_perp -> bf_fx に Lead-Lag 構造があると言ってよいかを、方向別に YES / HOLD / NO で返す観測器を作ることです。既存の signal engine 側にはすでに Lead-Lag の診断系があり、best_tau を探索して score と pairs を出し、LEADLAG_DIAG や SIGNAL(leadlag) を発行する流れまでは入っていました。たとえば _best_leadlag_score() では、tau=1..max_lag_sec を走査して、t_ms - tau_ms の lead 側リターンと lag 側リターンの相関が最大になる遅れ秒数を選んでいます。
for tau in range(1, self.leadlag_max_lag_sec + 1):
tau_ms = tau * 1000
xs: List[float] = []
ys: List[float] = []
for t_ms in sample_times:
if t_ms < ts_local - int(self.leadlag_window_sec * 1000):
continue
lag_r = self._return_at(lag_market, t_ms, delta_ms)
lead_r = self._return_at(lead_market, t_ms - tau_ms, delta_ms)
if lag_r is None or lead_r is None:
continue
xs.append(lead_r)
ys.append(lag_r)
if len(xs) < self.leadlag_min_pairs:
continue
c = _corr(xs, ys)
if c > best_score:
best_score = c
best_tau = tau
best_pairs = len(xs)
ただ、ここで返ってくるのはあくまで「それっぽい時間差が見えているか」の診断です。J 系統としてほしいのはそこから一段先で、その関係が future outcome とつながっているかまで含めて読むことでした。そこで今回は、signal engine の LEADLAG_DIAG をそのまま執行トリガーに使うのではなく、service 側で別に forward tracker と J judge を置く方針にしました。結果として J-LeadLag は、既存の診断を材料にしつつも、最終的には service 側で構造判定する層になっています。実際、_JLeadLagStructureTracker は relation の強さと 10s / 30s / 60s の future facts を受け取って、方向別に state / reason を返す構造です。
もう一つ大きかったのは、anchor を SIGNAL(leadlag) ではなく LEADLAG_DIAG(signal_pass=true) に置いたことです。signal engine 側では、forward の診断イベントを必ず出したうえで、score_ok を通り、さらに cooldown も通ったときだけ SIGNAL(leadlag) を追加発行する流れになっています。m
このまま SIGNAL を anchor にすると、signal cooldown の影響で観測母数が歪みます。今回は「Lead-Lag 構造があるか」を見たいので、執行や signal 発火頻度の事情は切り離したかった。だから signal_pass=true の LEADLAG_DIAG を anchor にし、その時点の lag_mid を基準価格として future outcome を測る設計にしました。_build_leadlag_diag_event() に lag_mid を持たせたのも、その anchor 価格を service 側へきちんと引き渡すためです。
signal_pass = bool(score_ok and spread_ok and data_ok and stability_ok)return {
"event_type": "LEADLAG_DIAG",
...
"lag_mid": lag_mid,
"best_tau_sec": best_tau,
"score": best_score,
"stability_metric": stability,
"pairs": best_pairs,
"side_hint": side_hint,
"pass_flags": {
"score_ok": score_ok,
"spread_ok": spread_ok,
"data_ok": data_ok,
"stability_ok": stability_ok,
},
"signal_pass": signal_pass,
}
そして今回の J-LeadLag では、判定対象もかなり絞りました。config と builder 側を見ると、v1 は lead_market=binance_perp, lag_market=bf_fx 固定で、主判定 horizon を 30 秒、その補助として 10 秒と 60 秒を持つ設計です。multi_market_probe_service
ここで大事なのは、最初から multi-lead 合成や hedge 接続まで広げなかったことです。Lead-Lag とひとくちに言っても、複数市場を合成し始めると relation の意味が一気に曖昧になりますし、hedge や execution feasibility を混ぜると、構造がないのか、構造はあるが取れないのかが分かりにくくなります。今回はそこを避けるために、対象市場をひとつに固定し、J の責務も「構造の白黒判定」に限定しました。
その方針は、J judge の入口にも表れています。on_tick() では、まず relation 側から pairs / best_tau_sec / score / stability_metric を取り、そこから ready_ok と relation_weak を作っています。さらに future facts は 10s / 30s / 60s を direction 別に取り出し、最後に _judge_direction() へ渡して state と reason に落としています。つまり今回の判定器は、quality → ready → relation → future outcome の順に読む構造です。
pairs = float(relation.get("pairs", 0.0))
best_tau_sec = float(relation.get("best_tau_sec", 0.0))
score = float(relation.get("score", 0.0))
stability = float(relation.get("stability_metric", 0.0))
ready_ok = pairs >= float(self.leadlag_min_pairs) and best_tau_sec > 0.0
relation_weak = (
score < self.relation_min_score
or stability < self.relation_min_stability
)state, reason = self._judge_direction(
quality_ok=quality_ok,
ready_ok=ready_ok,
relation_weak=relation_weak,
facts_10s=facts_10s,
facts_30s=facts_30s,
facts_60s=facts_60s,
)
この順番にした理由はシンプルで、Lead-Lag をただの相関スコア装置にしたくなかったからです。relation が見えても future outcome が弱ければ YES にはしたくないですし、逆に一時的に relation が弱くても、観測不足なのか構造否定なのかは分けて扱いたい。実際 _judge_direction() でも、quality 不足なら HOLD_QUALITY_ISSUE、ready 不足なら HOLD_NOT_READY、30 秒の sample 不足なら HOLD_LOW_SAMPLE と、先に HOLD 系を明示的に返すようになっています。relation が弱い場合も即 NO にはせず、30 秒の evidence が弱いときだけ NO_NO_RELATION、そうでなければ HOLD_RELATION_PENDING にしています。
このあたりは前回の J-Reversion と同じで、今回は YES 条件を鋭くするよりも、NO を軽く出しすぎないことを重視しました。
if not quality_ok:
return "HOLD", "HOLD_QUALITY_ISSUE"
if not ready_ok:
return "HOLD", "HOLD_NOT_READY"samples_30 = float(facts_30s.get("samples_total", 0.0))
if samples_30 < float(self.min_samples_main):
return "HOLD", "HOLD_LOW_SAMPLE"...
if relation_weak:
if hit_30 < self.no_hit_rate_pct and (not edge_30):
return "NO", "NO_NO_RELATION"
return "HOLD", "HOLD_RELATION_PENDING"
要するに今回の実装方針は、Lead-Lag を「lead が何秒先行しているかを見る診断」から、future outcome を伴った構造判定器へ進めることでした。そのために、対象市場を固定し、anchor を LEADLAG_DIAG(signal_pass=true) に置き、30 秒主判定の YES / HOLD / NO に落とす。逆に、tau 安定性の新規導入や multi-lead 合成、hedge 接続のような話は今回は意図的にやっていません。そこまで一気に広げると、今回作りたかった「J-LeadLag の骨格」がまた曖昧になるからです。
3. 今回やったこと:anchor・future outcome・J判定を配線した
今回の実装で実際にやったことを一言でまとめると、Lead-Lag 診断をそのまま使うのではなく、anchor → future outcome → J 判定 の3段に分けて配線し直した、ということになります。もともとの signal engine 側には、lead 側と lag 側の時間差相関を見て best_tau を出す仕組みがありました。ここで見ているのは、lag_market の各サンプル時刻に対して、tau 秒前の lead_market のリターンを合わせ、相関が最大になる遅れ秒数を選ぶ処理です。つまり、今回の J-LeadLag はこの既存診断を起点にしつつ、その先の future facts と構造判定を service 側で新しく足した形です。
def _best_leadlag_score(
self,
*,
lead_market: str,
lag_market: str,
ts_local: int,
delta_ms: int,
) -> Tuple[int, float, int]:
best_tau = 0
best_score = -1.0
best_pairs = 0
sample_times = [t for t, _m in list(self._mid_hist.get(lag_market, []))[-self.leadlag_eval_points:]] for tau in range(1, self.leadlag_max_lag_sec + 1):
tau_ms = tau * 1000
xs: List[float] = []
ys: List[float] = []
for t_ms in sample_times:
if t_ms < ts_local - int(self.leadlag_window_sec * 1000):
continue
lag_r = self._return_at(lag_market, t_ms, delta_ms)
lead_r = self._return_at(lead_market, t_ms - tau_ms, delta_ms)
if lag_r is None or lead_r is None:
continue
xs.append(lead_r)
ys.append(lag_r)
if len(xs) < self.leadlag_min_pairs:
continue
c = _corr(xs, ys)
if c > best_score:
best_score = c
best_tau = tau
best_pairs = len(xs)
return best_tau, best_score, best_pairs
最初の追加は anchor の整備です。signal engine 側では LEADLAG_DIAG を組み立てる段階で、best_tau_sec / score / stability_metric / pairs / signal_pass に加えて lag_mid を持たせました。service 側で future outcome を測るには、「その時点の lag 側基準価格」が必要になるからです。ここでは signal_pass も引き続き残しており、後段ではこの LEADLAG_DIAG(signal_pass=true) を anchor として使います。つまり今回は SIGNAL を基準にしたのではなく、診断イベントのうち PASS したものをそのまま future 観測の起点にしています。
lag_mid = _safe_float(self._latest_ticks.get(lag_market, {}).get("mid", 0.0), 0.0)
...
signal_pass = bool(score_ok and spread_ok and data_ok and stability_ok)return {
"event_type": "LEADLAG_DIAG",
...
"lead_exchange": lead_market,
"lag_exchange": lag_market,
"lag_mid": lag_mid,
"direction": direction,
"best_tau_sec": best_tau,
"score": best_score,
"stability_metric": stability,
"pairs": best_pairs,
...
"signal_pass": signal_pass,
}
次に足したのが、service 側の _LeadLagForwardTracker です。ここでやっていることはかなり単純で、LEADLAG_DIAG(signal_pass=true) を受け取ったら pending anchor として保持し、その後に流れてくる MARKET_SAMPLE から 10s / 30s / 60s 後の lag 側変化を順次確定していく、というものです。builder 側を見ると、この tracker は lead_market=binance_perp, lag_market=bf_fx を基本ペアにして作られ、horizon や quality window もここで注入されています。
そして main loop 側では、MARKET_SAMPLE を受けるたびに forward tracker を更新し、その直後に _update_j_leadlag(ts_ms) を呼んで J 側の state を再計算するように配線しています。つまり今回の Lead-Lag 判定は、診断イベントが立った瞬間だけでなく、その後の market sample の成熟に合わせて少しずつ事実が溜まっていく構造です。
if kind == "MARKET_SAMPLE":
update_multi_market_probe_market(**payload)
ts_ms = int(_coerce_float(payload.get("ts_local", payload.get("recv_ts_ms", 0.0)), 0.0, 0.0))
for tracker in leadlag_forward_trackers:
tracker.on_market_sample(payload)
_update_j_leadlag(ts_ms)
future outcome の定義も今回の実装で固定しました。方向は side_hint から long / short に正規化し、lag 側の変化量は signed bps に変換しています。long なら lag_mid(t+h) - lag_mid(t) をそのまま使い、short なら符号を反転するので、どちらも「期待方向に動けば正になる」ように揃います。これにより、horizon ごとに samples_total / hit_rate_pct / delta_latest / delta_mean を方向別に持てるようになりました。記事として見ると地味ですが、今回の要点はここです。Lead-Lag に対する future facts をようやく持てたので、J が単なる relation score のラッパーではなくなりました。実装後は Prometheus 側にも 30s 主判定用の hit rate や mean delta だけでなく、horizon 別の samples / delta も追加されています。
obx_mmarb_j_leadlag_samples_30s = Gauge(
"obx_mmarb_j_leadlag_samples_30s",
"Multi-market probe J-LeadLag directional matured samples at 30s horizon",
_MMARB_J_LEADLAG_LABELS,
)
obx_mmarb_j_leadlag_hit_rate_30s_pct = Gauge(
"obx_mmarb_j_leadlag_hit_rate_30s_pct",
"Multi-market probe J-LeadLag directional hit rate (%) at 30s horizon",
_MMARB_J_LEADLAG_LABELS,
)
obx_mmarb_j_leadlag_delta_mean_30s_bps = Gauge(
"obx_mmarb_j_leadlag_delta_mean_30s_bps",
"Multi-market probe J-LeadLag directional mean signed delta (bps) at 30s horizon",
_MMARB_J_LEADLAG_LABELS,
)
そのうえで、これらの future facts を読んで最終的に YES / HOLD / NO を返す _JLeadLagStructureTracker を追加しました。builder 側では j_leadlag_eval セクションから、対象市場、3本の horizon、relation 閾値、main / aux の最小サンプル数などを読み込んで tracker を作っています。ここで Reversion と同じく、「観測機が何を読んで J 判定するか」を config とクラスの両方で固定したわけです。relation 側は min_pairs / corr_enter / stability_min を既存の signal 設定から流用しつつ、J 専用の min_samples_main / yes_hit_rate_pct / no_hit_rate_pct などを別に持たせています。
trackers: list[_JLeadLagStructureTracker] = [
_JLeadLagStructureTracker(
lead_market=lead_default,
lag_market=lag_default,
horizons_sec=(h10, h30, h60),
leadlag_min_pairs=leadlag_min_pairs,
relation_min_score=relation_min_score,
relation_min_stability=relation_min_stability,
min_samples_main=coerce_int(cfg.get("min_samples_main", 80), 80, 1, 1000000),
min_samples_aux=coerce_int(cfg.get("min_samples_aux", 30), 30, 1, 1000000),
...
)
]
実際の判定では、quality、ready、relation、future facts を順に読んでいます。quality が悪ければ HOLD_QUALITY_ISSUE、relation readiness が足りなければ HOLD_NOT_READY、30 秒の matured sample が足りなければ HOLD_LOW_SAMPLE。その先で 30 秒 main の hit rate と signed delta を見て、一定条件を満たせば YES_LEADLAG_CONFIRMED、弱ければ NO_NO_RELATION や NO_NO_LEADLAG_30S、中間なら HOLD_RELATION_PENDING や HOLD_ONLY_60S を返す構造です。ここで大事だったのは、NO を軽く出さないことでした。relation が弱いだけで即 NO にするのではなく、future side の evidence も弱いときに限って NO へ倒すようにしています。
最後にやったのが可視化です。Prometheus には J-LeadLag 用に state_code / reason_code / ready_flag / quality_flag / samples_30s / hit_rate_30s_pct / delta_mean_30s_bps / delta_latest_30s_bps を追加し、更新関数 update_multi_market_j_leadlag_state(...) も足しました。これで J の最終出力を exporter の側で機械可読な数値へ落とせるようになりました。
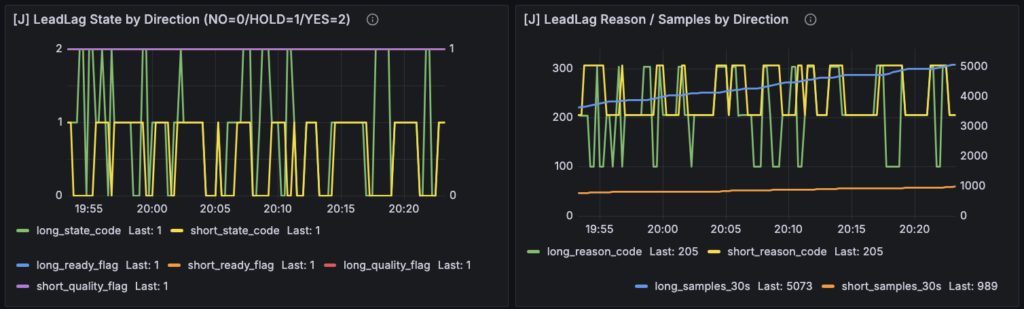
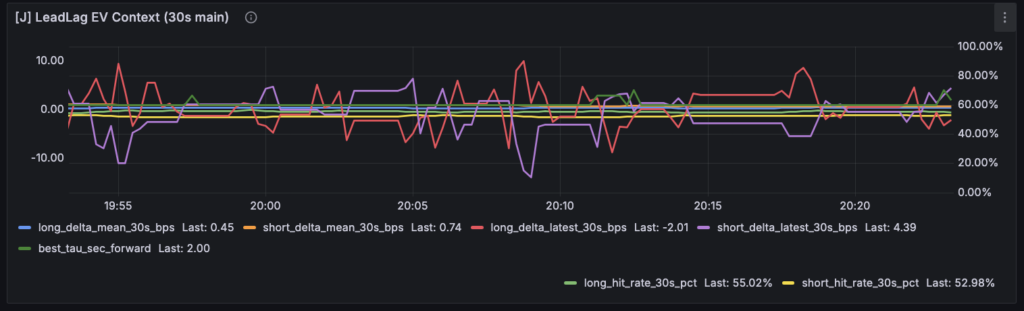
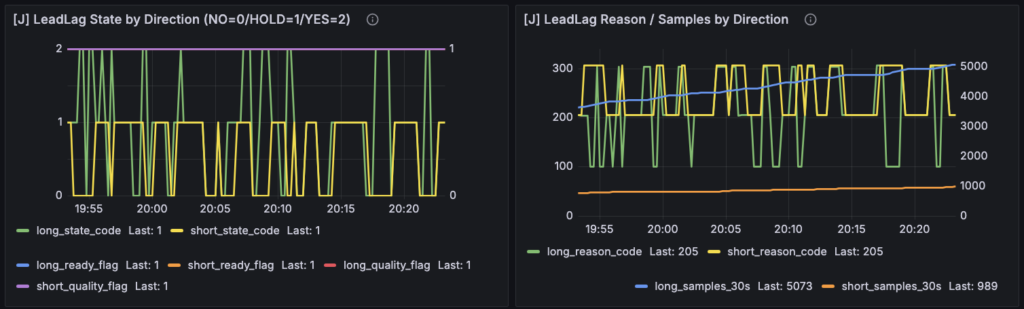
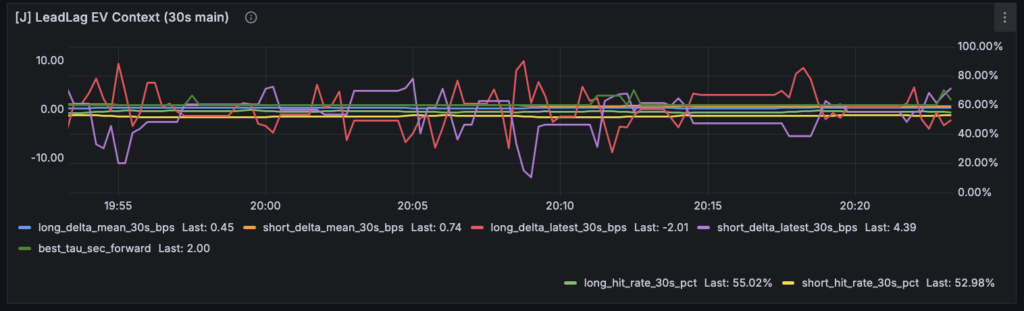
Grafana 側では、その結果を読むために [J] LeadLag State by Direction、[J] LeadLag Reason / Samples by Direction、[J] LeadLag EV Context (30s main) の3枚を追加しています。state と reason を分けたのは、YES/HOLD/NO の結果だけでなく、「なぜそこに留まっているのか」を同時に読めるようにするためです。EV Context は 30 秒主判定の補助事実として、hit rate、signed delta、best_tau を一枚に並べています。
ここまでをまとめると、今回やったのは単なるメトリクス追加ではありません。
既存の Lead-Lag 診断に対して、
- PASS した診断を anchor として取る
- その anchor から 10s / 30s / 60s の future outcome を蓄積する
- その事実をもとに J-LeadLag が方向別に YES / HOLD / NO を返す
- その state / reason を Prometheus と Grafana で読めるようにする
という一連の流れを、ようやくひとつの系として通した、ということです。
4. コードで見る今回の要点:qualityとdirectionの意味を整理した
今回の実装でいちばん大きかったのは、J-LeadLag を追加したことそのものよりも、何を quality と呼び、何を direction と呼ぶのかを整理できたことだったと思っています。
観測器を作っていると、数値やメトリクスは増やせます。
実際、今回も state、reason、samples、hit rate、delta、best_tau まで出せるようになりました。
ただ、これらは増やしただけでは意味を持ちません。
重要なのは、それぞれが何を表していて、どこまでを同じ意味として読んでよくて、どこからを別物として切り分けるべきか、です。
今回そこがはっきり出たのが、quality と direction の二つでした。
quality は「構造の弱さ」ではなく「観測品質」であるべきだった
最初の実装では、quality 側に relation failure が混ざっていました。
具体的には、Lead-Lag の quality 履歴を積むときに signal_pass 相当の条件が入っていて、score や stability が弱いだけでも quality bad として扱われる余地がありました。
でもこれは、意味としてかなり不自然です。
quality という言葉で本来見たいのは、
データがちゃんと来ているか
観測が stale していないか
spread 条件が破綻していないか
といった、観測機そのものの健全性です。
一方で、
score が弱い
stability が足りない
relation がまだ薄い
というのは、観測対象の構造側の問題です。
この二つが混ざると何が起きるかというと、
本当は「構造がまだ弱い」だけなのに、Grafana 上では「品質が悪い」ように見えてしまいます。
実際、最初のパネルでは、
ready は立っている
samples も十分ある
それなのに quality_flag が頻繁に 0 に落ちる
という少し読みにくい状態になっていました。
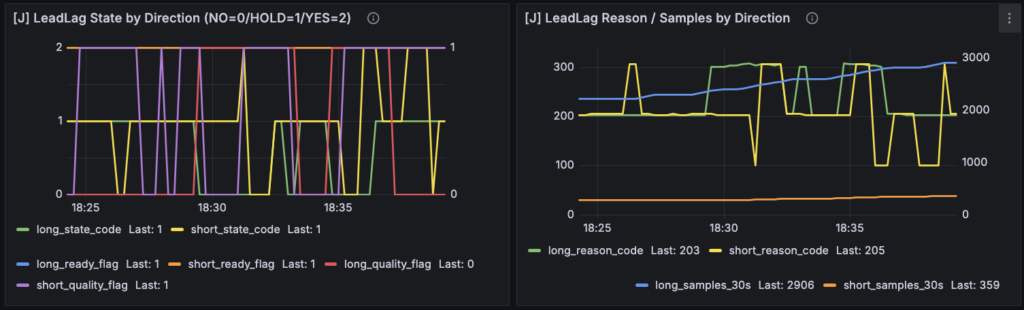
この状態だと、J-LeadLag が何を返しているのかは見えても、
なぜその判定になったのか が分かりにくくなります。
そこで今回は、quality の定義をかなり素朴なものに戻しました。_LeadLagForwardTracker.on_leadlag_diag() では、quality を data_ok and spread_ok に限定しています。
data_ok = bool(pass_flags.get("data_ok", False))
spread_ok = bool(pass_flags.get("spread_ok", False))
quality_ok = bool(data_ok and spread_ok)
この変更で見えるようになったのは、J-LeadLag の中で
quality の問題
relation の問題
future outcome の問題
を別々に読む土台です。
言い換えると、今回ようやく
「観測器が壊れているのか」
と
「観測対象に構造がないのか」
を別のものとして扱えるようになりました。
これはかなり大きいです。
構造がないのに観測器のせいにするのも危険ですし、観測器が悪いのに構造がないと決めつけるのも危険だからです。
今回の修正で、少なくとも quality_flag は「観測品質」の近くへ戻りました。
その結果、Grafana 上でも quality の跳ね方はだいぶ落ち着きましたし、次からは reason を素直に読める段階に一歩近づいたと思っています。
direction は「今の値動き」ではなく「relationを作った向き」で付けるべきだった
もう一つ大きかったのが、direction の意味整理です。
Lead-Lag を方向別に読む以上、
long / short のラベルが何を表しているのかはかなり重要です。
最初の実装では、この方向ラベルを current lead return から作っていました。
つまり、「今この瞬間の lead 側の値動きが上か下か」で side_hint を決めていたわけです。
ただ、Lead-Lag の relation 本体はそういう見方をしていません。
signal engine 側でやっているのは、あくまで best_tau 秒前の lead move が今の lag にどう対応しているか です。_best_leadlag_score() でも、lag 側の各時点に対して、t_ms - tau_ms の lead return を使って相関を測っています。mmarb_signal_engine
つまり、relation を作った“向き”と、anchor 時点の current move は、必ずしも同じとは限りません。
ここがズレたまま方向別集計をすると、
long / short の samples
hit rate
delta_mean
最終的な state / reason
まで、全部に少しずつノイズが入ります。
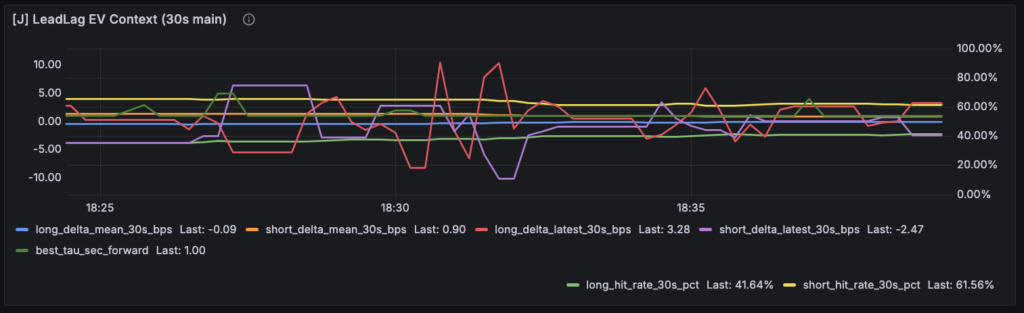
そこで今回は、side_hint を best_tau に整合した lead move から決めるように直しました。_build_leadlag_diag_event() では、まず ts_local - best_tau*1000 の lead return を取り、それが得られない場合だけ current return にフォールバックする形にしています。
lead_move_aligned = None
if best_tau > 0:
lead_move_aligned = self._return_at(
lead_market,
ts_local - (best_tau * 1000),
delta_ms,
)
if lead_move_aligned is None:
lead_move_aligned = self._return_at(lead_market, ts_local, delta_ms)side_hint = (
"SELL_BASE_BUY_REF"
if (lead_move_aligned is not None and lead_move_aligned < 0.0)
else "BUY_BASE_SELL_REF"
)
この変更で見えるようになったのは、direction 別の数値を「それっぽい分類」ではなく、relation を作った向きに近いものとして読む 土台です。
もちろん、これで direction の問題がすべて解決したわけではありません。
Lead-Lag そのものが片方向に偏る場面はありますし、signal_pass の立ち方によっても方向別母数は偏ります。
ただ少なくとも今回の修正で、方向ラベル自体の純度はかなり上がりました。
今回の実装で何が見えるようになったのか
ここまでの変更で、J-LeadLag では少なくとも次のことが見えるようになりました。
ひとつは、Lead-Lag を quality / ready / relation / outcome の4層に分けて読めるようになったことです。
以前は、Lead-Lag はほぼ診断系で、
score が高いか
best_tau が出ているか
signal_pass が立つか
あたりを見るくらいでした。
でも今は、その先に
quality は安定しているか
ready は立っているか
30s main に十分な samples があるか
そのうえで hit rate や delta_mean がどうか
まで、層を分けて見られます。
これはかなり重要です。
J 系統で本当に知りたいのは、「何かあるかどうか」以上に、どこで止まっているのか だからです。
もうひとつ見えるようになったのは、direction 別の非対称性です。
long 側は samples が多いのか
short 側は hit rate が高いのか
どちらが HOLD に張り付きやすいのか
どちらが NO に落ちやすいのか
こういった違いは、今回の J-LeadLag でかなり素直に見えるようになりました。
これは、観測器としてかなり良い変化です。
Lead-Lag を単一スコアに潰していたら、この非対称性はほとんど見えなかったはずです。
理想的には何が見えるようになるべきか
ただし、今回の時点では「見えるようになった」と「読みやすくなった」はまだ一致していません。
今の Grafana では、たとえば [J] LeadLag EV Context (30s main) に
hit rate
delta_mean
delta_latest
best_tau
が同居しています。
これは情報としては正しいのですが、
一枚のパネルに複数の意味が載りすぎている ので、解釈コストがまだ高いです。
理想的には、J 系統のパネルは
いま何判定か
なぜその判定か
その判定を支える最低限の事実は何か
が、一目で分かるべきです。
たとえば今後は、
State パネル
Reason パネル
Samples / Ready パネル
30s main の edge パネル
のように役割をさらに分けた方がよいかもしれません。
特に EV Context は、現状だと「とりあえず必要そうなものを載せてある」段階に近いです。
観測器としては有用ですが、実戦的な判定機としては、まだ少し読みにくい。
今回の実装で見えるようになったものを、次は 迷わず読める形に削る 必要があると思っています。
まだ見えていないものは何か
逆に言うと、今回まだ見えていないものもはっきりしています。
まず、reason の分布 がまだ十分に読めていません。
state は見えるようになりましたし、reason_code も出るようになりました。
でも、いまの段階では
どの reason が多いのか
何が主要ボトルネックなのか
時間帯によって何 reason に偏るのか
まではまだ整理できていません。
次に見たいのは、単発のスクショではなく、
reason が時系列でどう分布しているか です。
次に、30s main の weak / strong の境界 もまだ見えていません。
現時点では、30 秒主判定で edge が薄いことまでは読めます。
でも、それが
本当に構造が弱いのか
閾値が少し厳しすぎるのか
direction 別に片側だけ生きているのか
までは、まだ完全には分かりません。
これは今後、reason と samples をあわせて読むことで少しずつ見えてくるはずです。
さらに言えば、tau 安定性 もまだ見えていません。
今回は intentionally 入れていませんが、Lead-Lag を構造としてもっと強く読むなら、
best_tau が固定的に出ているのか
それとも毎回ばらついているのか
は、いずれ見たくなるはずです。
ただ、いまはまだそこまで行く段階ではないと思っています。
今回まず必要だったのは、relation と future outcome をつないで J-LeadLag を立ち上げることだったからです。
今回見えてきたのは「構造」そのものより、「読むための条件」だった
ここまでをまとめると、今回の実装で一気に構造が見えた、というよりは、
構造を読むために何を切り分ける必要があるかが見えてきた
という方が正確です。
quality は quality として分ける
direction は relation 整合で付ける
state と reason は別で読む
30s main の edge と samples は切り離す
パネルは情報を増やすより、責務を分ける
こうしたことが、今回かなりはっきりしました。
つまり今回は、Lead-Lag の「答え」が見えた回というより、
Lead-Lag を答えとして読める形へ近づけた回 だったと思っています。
次に必要なのは、新しいロジックを足すことよりも、
いま出るようになった reason と facts を、人間が迷わず読める形へ整えることです。
J-LeadLag は一応動きました。
これからは、それを「読める判定機」に削っていく段階に入ります。
5. 現在地:J-LeadLagは動いたが、まだ“読みにくい”
ここまでで、J-LeadLag は少なくとも「存在しないもの」ではなくなりました。
state も reason も exporter に出ていて、Grafana 上でも方向別に追える。quality と relation の意味も以前より素直に分かれるようになり、future facts も 10s / 30s / 60s で積めるようになっています。
この意味では、今回の到達点はかなり明確です。
J-LeadLag は一応、観測器として動いている。まずここまでは言ってよいと思います。
ただし、ここで次の問題が出てきます。
それは、「動く」と「読める」は別だということです。
実際、今回パネルを眺めていて感じたのは、見える情報量そのものは増えた一方で、最終的に何を読めばよいのかはまだ即断しづらい ということでした。たとえば state が HOLD や NO を返していても、それが relation の弱さによるものなのか、30 秒 main の evidence 不足なのか、あるいは単に sample 側の事情なのかを、その場でぱっと読み切るにはまだ少し頭を使います。
この「少し頭を使う」が、観測器としては意外と重いです。
開発中はそれでも読めます。
自分が何を入れて、どこを触って、何を直したかを知っているからです。
でも、実戦的な判定機として考えるなら、理想はそこではありません。
できれば、
いまの state は何か
それはどの理由でそうなっているか
次に見るべき情報は何か
が、なるべく低コストで分かる方がいい。
今の J-LeadLag は、そこへ向かう途中にいます。
いまのパネルは「情報としては正しい」が「判定器としては少し厚い」
今回追加したパネル構成は、
State
Reason / Samples
EV Context
の3枚です。
これは観測器を立ち上げる段階としては妥当でした。state だけでは解釈不足ですし、reason だけでは方向感がない。future facts も見えないと、そもそも J をどう読むのか分からないからです。
ただ、ここまで揃ってくると逆に、パネルごとの責務がまだ少し重なっていることも見えてきます。
とくに [J] LeadLag EV Context (30s main) はその典型でした。
このパネルには、
30秒の hit rate
30秒の mean delta
30秒の latest delta
best_tau
が並んでいます。
どれも必要な情報ではあります。
でも、これらは同じ意味の情報ではありません。
hit rate は方向整合の頻度です。
mean delta は平均的な向きの強さです。
latest delta は直近観測のノイズも含んだ局所値です。
best_tau は relation 側の時間差診断です。
つまりここでは、future outcome の要約、局所値、relation の一部が、ひとつのパネルに同居しています。
その結果、「何を主に読めばいいのか」がまだ少し曖昧です。
これは悪い実装というより、むしろ 立ち上げ直後の観測器らしい状態 だと思っています。
必要そうなものをまず並べてみて、そのあとに「結局どれを残すべきか」を削っていく段階です。
いま欲しいのは、情報の追加より“責務の分離”
今回やっていて改めて感じたのは、観測器を読みやすくするうえで重要なのは、新しい指標を足すことよりも、各パネルが何のためにあるのかをはっきりさせること だということです。
たとえば state パネルの役割は、
「いま YES / HOLD / NO のどこにいるか」を知ることです。
reason パネルの役割は、
「なぜそこにいるのか」を知ることです。
samples 系は、
「その判定に最低限の母数があるか」を知ることです。
そして edge 系は、
「future outcome として本当に方向性が残っているか」を見ることです。
本来は、この責務がもっときれいに分かれていた方が読みやすいはずです。
今の J-LeadLag は、その構成要素自体は揃ってきました。
でも、まだ 人間が実戦で読むための整理 までは終わっていない。
だから「動いたが、まだ読みにくい」という感覚になるのだと思います。
今回の現在地は「構造が見えた」ではなく「読む入口ができた」
もうひとつ大事なのは、今回の到達点を大きく言いすぎないことです。
J-LeadLag が実装され、quality も落ち着き、direction ラベルの純度も改善しました。
それによって、少なくとも「Lead-Lag を J の構造判定器として観測できる状態」には入りました。
ただし、それはまだ
Lead-Lag 構造が明確に確認できた
という意味ではありません。
現時点ではむしろ、
30秒 main では edge がまだ薄い
state / reason はそれなりに揺れる
direction別の偏りはあるが、その意味はまだ読み途中
という段階です。
言い換えると、今回見えるようになったのは「答え」そのものより、
答えを読む入口 です。
この違いはかなり大きいと思っています。
観測器を作っていると、メトリクスが増えたり、パネルが埋まったりすると、それだけで前進したような感覚が出ます。もちろん今回も前進ではあります。
ただ、J 系統に関して本当に大事なのは、「値が出ること」ではなく「判断に使えること」です。
その意味では、今回の J-LeadLag はまだ途中です。
でも途中であること自体が、今はむしろ健全だと思っています。無理に YES / NO を言い切るより、まずは HOLD を含めてどう読むかを整理する方が、観測器としては筋がよいからです。
いまのボトルネックは、構造そのものより“解釈”にある
ここまで来ると、次のボトルネックもかなりはっきりします。
それは、Lead-Lag の構造があるかどうか以前に、いま出ている state / reason / facts をどう読むのが最も自然か がまだ固まり切っていないことです。
つまり、次の課題はロジック不足というより、解釈系の整理です。
reason_code をどう読むか
どの reason を重く見るか
30秒 main と 60秒補助をどう併記するか
delta_latest をどこまで残すか
best_tau を常時見せる必要があるのか
こういったことを整理しないと、J-LeadLag は「情報はあるが迷うパネル」のままになりやすい。
今回の現在地は、まさにそこです。
実装としてはかなり前に進みました。
でも読み手としては、まだ「何を見ればよいか」を毎回自分で組み立て直している。
この状態を抜けて、見れば判断の筋が自然に立つ ところまで持っていくのが、次のフェーズだと思っています。
6. 今後やること:reasonを読み、パネルを実戦向けに削る
ここまでで、J-LeadLag の大枠は一応できました。
anchor を取り、future outcome を積み、J が YES / HOLD / NO を返し、その結果を Grafana で見られるところまでは来ています。
ただ、今回の到達点は「完成」ではなく、むしろ
ようやく削る準備が整った段階
だと思っています。
次にやるべきことは、新しい指標を増やすことではありません。
いま出ている state、reason、samples、delta の中から、実際の判定に必要なものだけを残し、読む順番を固定することです。
今回の J-LeadLag は、立ち上げ直後の観測器としてはかなり素直に動いています。
でもその一方で、まだ「分かる人が頑張って読む」側面が強い。
これを、見れば自然に判断の筋が立つパネル に寄せていく必要があります。
そのために、次回まずやりたいのは reason をちゃんと読むことです。
いまは reason_code を exporter でも Grafana でも出しています。prometheus_exporter.py 側にも obx_mmarb_j_leadlag_reason_code を追加していて、state と並べて reason を追えるようにはなりました。prometheus_exporter
ただ、現時点では「reason が出ている」ことと、「reason を使って判断できる」ことのあいだに、まだ少し距離があります。
次に必要なのは、
どの reason がどれくらい多いのか
どの reason が実質的なボトルネックなのか
HOLD 系と NO 系のどちらに詰まりやすいのか
long / short で reason の偏りがあるのか
を、実際の RUN の中で読んでいくことです。
ここが見えてくると、J-LeadLag の改善もかなり具体的になります。
たとえば HOLD_LOW_SAMPLE が多いなら sample 要件の問題ですし、HOLD_RELATION_PENDING が多いなら relation 閾値の切り方を見直す余地があります。NO_NO_LEADLAG_30S に張り付きやすいなら、30 秒主判定の解釈自体を再検討した方がよいかもしれません。
逆に、この reason を読まずに state だけ見てしまうと、
「YES が少ない」「NO が多い」
という雑な感想で終わりやすい。
次回はそこを避けて、なぜそうなっているのかを reason ベースで読む ところから入りたいと思っています。
そのうえで、パネルももう少し実戦向けに削りたいです。
今の Grafana は、観測器を立ち上げる段階としては十分に役立ちました。
state、reason、samples、30 秒 main の edge 情報が一通り見えるので、何が起きているかを追うには困りません。
ただ、これから欲しいのは「全部見えること」よりも、
必要なものだけ見て迷わず判断できること です。
たとえば [J] LeadLag EV Context (30s main) は、現時点では情報を詰め込んだ確認用パネルとしては機能していますが、日常的に読むにはまだ少し厚いと感じています。hit_rate_30s_pct、delta_mean_30s_bps、delta_latest_30s_bps、best_tau_sec を同じ場所で見せているので、future facts と relation 補助情報が一枚に同居している状態です。
この形は立ち上げ時には便利ですが、実戦で毎回見るなら、
state は state だけ
reason は reason だけ
sample は sample だけ
edge は edge だけ
と、もっと責務を分けた方が読みやすいはずです。
次回はその観点で、
何を残すか
何を分離するか
何をむしろ落とすか
を見直していくつもりです。
必要なら best_tau は補助パネルへ逃がすかもしれませんし、delta_latest のような局所値も、常時表示ではなく確認用へ下げた方がよいかもしれません。逆に、30 秒 main の samples と reason のつながりは、もっと近い場所で見えた方が判断しやすい可能性があります。
要するに次回やりたいのは、J-LeadLag をさらに高機能にすることではなく、
判定器としての読み順を固定し、余分な迷いを減らすこと です。
今回の記事のタイトルには「判定器へ昇格させた話」と書きましたが、実際にはまだ “判定器になりつつある観測器” くらいの段階です。
そこからもう一歩進んで、
state を見る
reason を見る
必要最小限の facts を確認する
そこで判断を終える
という流れを作れたら、J-LeadLag はかなり実戦的な形に近づくと思っています。
次回は、そのための整理を進めます。
新しいものを足す前に、まずは今あるものをちゃんと読めるようにする。
今回の続きとしてやるべきことは、そこだと思っています。