
こんにちは、ぼっちbotterよだかです。
前回は、観測器J系統の Lead-Lag を一旦判定器として立ち上げました。ただ、実際に Grafana へ載せてみると、state や reason は出ていても、まだ「読める」とは言いがたい状態でした。そこで今回は、新しいロジックを足すのではなく、J-Reversion / J-LeadLag を人間が低コストで解釈できる形へ削ることに集中しました。best_tau や score の意味整理、State / Reason / Ready-Quality / Components への分離、reason_code の可読化まで進めたことで、観測器として何が見えていて、何がまだ見えていないのかがようやく整理されてきました。
-

-
🛠️開発記録#482(2026/3/12)「multi_market_probe開発ログ ― 観測器J系統のLead-Lag判定器を一旦形にした話」
続きを見る
1. 今日の方針転換:J-Hedge を保留し、J系統を“読める判定機”に寄せる
今日の最初の判断は、J-Hedge を作る予定をいったんやめたことでした。もともとは J 系統のヘッジ部を足して、J-Reversion / J-LeadLag に続く三本目の判定器として形にしようとしていました。ただ、コードと設定をあらためて見直すと、現時点の hedge は「独立した収益源を持つ戦略」というより、signal を order intent に落とす際の補助ゲートに近い実装になっています。_evaluate_hedge() は、live なヘッジ市場があるか、spread が広すぎないか、Top of Book のサイズが足りるか、そこから見積もった expected_slip_bps が許容内かを返しているだけで、ここに future outcome を伴った J 判定はまだありません。返しているのは hedge_available、hedge_reason、expected_slip_bps、expected_fee_bps といった執行補助の材料です。
さらに設定側でも、この hedge はかなり意図的に「観測用途」に留められています。config.yaml では signals.hedge.enabled: false、order_intent.require_hedge_available: false になっており、コメントにも「国内単独執行の前提では必須にしない(観測用途)」と書いてあります。つまり今の土台は、bitFlyer を主戦場にした単独執行を前提にしていて、Binance perp などを実際の両脚として使う構造にはなっていません。しかも allowed_signal_types に入っているのは misprice_revert と leadlag だけで、hedge 自体は signal を通す本線ではない。ここで J-Hedge を先に作り込んでも、いまの自分の実行可能性に直結しにくいと判断しました。
この判断は、単に「今日は時間がないから削った」という話ではありません。観測器 J 系統の役割を、もう一段はっきりさせたという意味があります。J は執行器ではなく、まず「その市場ペアにそういう構造があると見てよいか」を YES / HOLD / NO で返す白黒判定層です。そう考えると、今の自分にとって先に詰めるべきなのは、実行不能な hedge 判定を増やすことではなく、すでにある J-Reversion / J-LeadLag を自分が低コストで読めるようにすることでした。実際、J-Reversion も J-LeadLag も exporter と dashboard にはすでに state / reason / ready / quality の骨格があり、そこに samples や hit rate、future delta をどう見せるかの方が今はボトルネックになっていました。Prometheus 側にも J-Reversion と J-LeadLag の state / reason / ready / quality / samples / hit rate はすでに用意されています。
ここで大事だったのは、「新しい判定器を足すこと」と「今ある判定器を信頼できる形にすること」を分けたことです。前者は見た目の進捗になりやすいですが、後者が弱いまま層を増やすと、最終的に何を見ればよいかが分からなくなります。実際、前日の時点の J-LeadLag も、State / Reason / Samples / EV Context のようなパネルはありましたが、best_tau や delta 系の意味が十分整理されておらず、「値は出ているが、どう読めばよいかで少し止まる」状態でした。J-Reversion 側にも EV Context や Correlation-Conditioned Reversion のような補助パネルはありましたが、J 判定器として最小限に読むには、まだ責務が少し厚い配置でした。
そこで今日の方針は、かなり単純に置き直しました。J-Hedge は保留する。その代わり、J-Reversion / J-LeadLag については、「何を見れば state を信じてよいのか」「どの数値が relation の強さで、どの数値が future outcome なのか」「ready と quality は state とどう違うのか」をいったん厳密に整理し、そのうえで Grafana を State / Reason / Ready-Quality / Components / Relation Strength の責務ごとに削り直す。つまり今日やったのは、新しい構造を発明することではなく、既存の J 系統を“見るもの”から“読むもの”へ寄せる作業でした。長い目で見ると、この判断はかなり重要だったと思っています。来週以降に別市場へ横展開したり、観測機を一段進めて執行やシミュレーションへ接続したりするにしても、その前提になるのは「いま出ている J 判定を自分がちゃんと読めること」だからです。
2. まず整理したこと:J-LeadLag の best_tau / score / stability / pairs は何を表しているのか
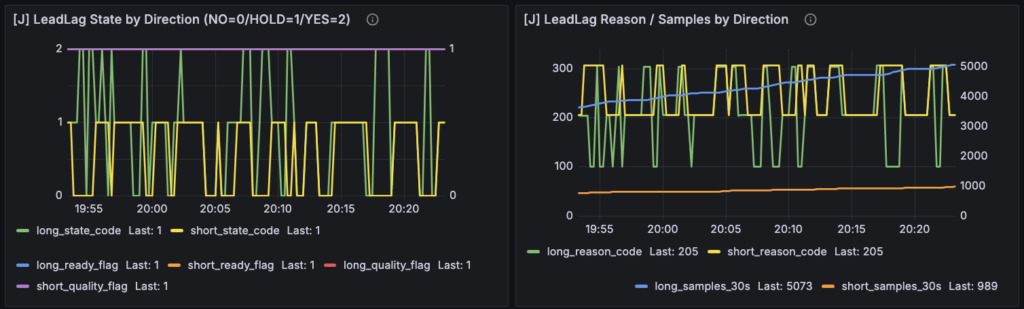
今回の作業で最初に詰まったのは、J-LeadLag の判定条件そのものより、そこで使っている数値の意味が自分の中でまだ十分に固定されていなかったことでした。前回までに J-LeadLag は一応動いていて、Grafana 上にも state / reason / hit rate / delta までは出るようになっていました。ただ、best_tau、score、stability、pairs といった relation 側の値については、「何となく Lead-Lag っぽさを表している」とは分かっていても、実際には何を計算していて、どこまでが ready の条件で、どこからが relation の強さなのかがまだ曖昧でした。このままだと、パネルに値が出ても読むたびに解釈し直すことになります。そこで今回は、まずここをコードベースで厳密に整理するところから入りました。
最初に確認したのは、best_tau_sec が何を意味しているのかです。Lead-Lag の時間差探索は MMArbSignalEngine._best_leadlag_score() でやっていて、ここでは tau=1..max_lag_sec を総当たりしています。そのたびに、lag 市場の各サンプル時刻 t_ms に対して、lead_market の t_ms - tau_ms と lag_market の t_ms のリターンを取って並べ、相関 c を計算し、もっとも相関が高かった tau を best_tau にしています。
for tau in range(1, self.leadlag_max_lag_sec + 1):
tau_ms = tau * 1000
xs: List[float] = []
ys: List[float] = []
for t_ms in sample_times:
if t_ms < ts_local - int(self.leadlag_window_sec * 1000):
continue
lag_r = self._return_at(lag_market, t_ms, delta_ms)
lead_r = self._return_at(lead_market, t_ms - tau_ms, delta_ms)
if lag_r is None or lead_r is None:
continue
xs.append(lead_r)
ys.append(lag_r)
if len(xs) < self.leadlag_min_pairs:
continue
c = _corr(xs, ys)
if c > best_score:
best_score = c
best_tau = tau
best_pairs = len(xs)
ここで重要なのは、見ているのが価格の実数値そのものではなく、_return_at() が返す mid price ベースの対数リターン だということです。_return_at() は、ある時刻 ts_ms の直前の mid と ts_ms - delta_ms の直前の mid を取り、math.log(current) - math.log(prev) を返しています。つまり Lead-Lag 判定の relation 側は、「何秒ずらすと価格が似るか」ではなく、「何秒ずらすと log return 列 が最も強く噛み合うか」を見ています。
def _return_at(self, market: str, ts_ms: int, delta_ms: int) -> Optional[float]:
hist = self._mid_hist.get(market)
if not hist:
return None
current = self._latest_before(hist, ts_ms)
prev = self._latest_before(hist, ts_ms - delta_ms)
if current is None or prev is None or current <= 0.0 or prev <= 0.0:
return None
return math.log(current) - math.log(prev)
この定義をはっきりさせたことで、best_tau_sec の役割もかなり整理されました。best_tau_sec は「Lead-Lag の強さ」そのものではなく、lead 市場の log return を何秒ずらすと、lag 市場の log return と最も整合するかを示す遅れ時間の推定値です。たとえば best_tau_sec=4 なら、「binance_perp の4秒前の return が、bf_fx の今の return と一番噛み合っている」という意味になります。逆に言えば、best_tau_sec 単体では構造の強さは分かりません。ここを強さの指標として読んでしまうと、解釈がすぐに濁ります。
強さの方を見ているのが score です。score は _best_leadlag_score() で選ばれた best_tau における最大相関係数 best_score をそのまま持ってきたものです。signal engine 側でも score_ok = best_score > self.leadlag_corr_enter として使われていて、signal を通す条件の一つになっています。つまり、best_tau_sec が「何秒遅れか」だとすると、score は「その遅れ仮説がどれくらい強く成り立っているか」です。今回 J-LeadLag の relation strength パネルに best_tau_sec と score を並べたのは、この役割分離を可視化するためでした。
stability_ok = stability >= self.leadlag_stability_min
score_ok = best_score > self.leadlag_corr_enter
signal_pass = bool(score_ok and spread_ok and data_ok and stability_ok)
さらに、score だけでもまだ一瞬の偶然相関を拾う可能性があります。そこで signal engine 側では、_build_leadlag_diag_event() で best_score の履歴を持ち、leadlag_corr_enter を超えた回数比率を stability として計算しています。コード上は、hist に best_score を積みながら、x > self.leadlag_corr_enter を満たす割合を stability にしています。つまり stability は「その相関強度が今だけではなく、直近履歴でも継続しているか」を見る値です。relation の強さを一発勝負ではなく、ある程度持続したものとして読むための補助になっています。
hist = self._leadlag_hist[key]
hist.append(best_score)
while len(hist) > self.leadlag_score_hist_len:
hist.popleft()
stability = (sum(1 for x in hist if x > self.leadlag_corr_enter) / float(len(hist))) if hist else 0.0
最後の pairs は、相関計算に使えた return ペア数です。これは単純な母数ですが、実際にはかなり重要です。relation が強く見えていても、サンプル数が極端に少なければ偶然の可能性が高くなります。そのため service 側の J-LeadLag でも、ready_ok は pairs >= leadlag_min_pairs and best_tau_sec > 0.0 と定義されていて、pairs は単なる補助情報ではなく、そもそも Lead-Lag を読んでよいかどうか の最低条件に組み込まれています。ここで初めて、「best_tau が出ている」だけではなく「その tau を支えるだけのペア数がある」ことが判定対象に入ります。
pairs = float(relation.get("pairs", 0.0))
best_tau_sec = float(relation.get("best_tau_sec", 0.0))
score = float(relation.get("score", 0.0))
stability = float(relation.get("stability_metric", 0.0))
ready_ok = pairs >= float(self.leadlag_min_pairs) and best_tau_sec > 0.0
relation_weak = (
score < self.relation_min_score
or stability < self.relation_min_stability
)
この整理をした結果、J-LeadLag の relation 側は、少なくとも自分の中では次のように分けて読めるようになりました。
best_tau_sec= 遅れ時間の推定値score= その遅れ仮説の強さstability= その強さが継続しているかpairs= その relation を支える母数
この4つをまとめて見ない限り、Lead-Lag の「relation がある / 弱い」を判断したことにはならない、ということです。逆に言うと、これまではこの4つが頭の中で少し混ざっていたので、best_tau が出ているだけで何かありそうに見えたり、score が弱いのに tau の値だけで引っ張られたりしていました。今回ここを整理したことで、best_tau_sec を単独の神秘的な数字として扱わずに済むようになりました。
この relation 側の整理と並行して、future outcome 側の数値も意味を固定しました。J-LeadLag では _LeadLagForwardTracker が direction ごとに horizon 別の samples_total / hits_total / delta_latest / delta_sum を持っていて、future_facts() ではそこから hit_rate_pct、delta_latest、delta_mean を返します。つまり、30秒主判定で見る hit_rate_30s_pct は「30秒後に期待方向で終わった割合」、delta_latest_30s_bps は「最新サンプルの signed delta」、delta_mean_30s_bps は「30秒 horizon における平均 signed delta」です。平均優位を見るのが delta_mean、直近の鮮度を見るのが delta_latest、そして符号整合の頻度を見るのが hit_rate、という役割分担です。
self._future_stats: dict[str, dict[int, dict[str, float]]] = {
"long": {
h: {"samples_total": 0.0, "hits_total": 0.0, "delta_latest": 0.0, "delta_sum": 0.0}
for h in self.horizons_sec
},
"short": {
h: {"samples_total": 0.0, "hits_total": 0.0, "delta_latest": 0.0, "delta_sum": 0.0}
for h in self.horizons_sec
},
}
実際、J-LeadLag の exporter 更新関数も、relation と future outcome を分けた形で値を受け取るように変わりました。update_multi_market_j_leadlag_state(...) には、従来の samples_30s / hit_rate_30s_pct / delta_mean_30s_bps / delta_latest_30s_bps に加えて、今回 score / stability / pairs / best_tau_sec を追加しています。Grafana 側でも [J-LeadLag] Relation Strength と [J-LeadLag] Edge Components (30s) を分離したので、relation と edge を同じパネルで無理に読まなくて済むようになりました。
ここまで整理してみて分かったのは、J-LeadLag が複雑に見えていた原因は、単純に条件が多すぎるからではなく、relation を表す数値と future outcome を表す数値が頭の中で混ざっていたから だということでした。best_tau / score / stability / pairs は relation の側、hit_rate / delta_mean / delta_latest は future outcome の側、ready / quality は観測や母数の側。この三層を分けてしまえば、J-LeadLag は少なくとも「何を見て何を言っているのか」がかなり素直になります。今回の作業はパネル改修そのものも大きかったのですが、その前提としてこの意味整理をコードベースでやり直したことが、実は一番重要だったと思っています。
3. 実装変更①:J-Reversion / J-LeadLag のパネルを責務ごとに分け直した
今回の実装変更で中心に置いたのは、新しい指標を増やすことではなく、すでに出ている指標を「何のために読むのか」で分け直すことでした。前日の時点でも、J-Reversion / J-LeadLag には state や reason、samples、delta 系の値はある程度出ていました。ただ、それらがまだ「立ち上げ直後の確認用パネル」という色合いが強く、relation 側の値と future outcome 側の値が同じ場所に並んでいたり、state / reason / samples が一枚のパネルで混ざっていたりして、読むたびに少し頭の中で再整理が必要な状態でした。これは観測器として値が出ていること自体は前進なのですが、判定機として見るとまだコストが高い。そこで今回は、J パネルを State / Reason / Ready-Quality / Components / Relation Strength に分解し、各パネルの責務をはっきり分けるところから入りました。実際、現在の dashboard では J-LeadLag 側に [J-LeadLag] State、[J-LeadLag] Ready / Quality (Last)、[J-LeadLag] Relation Strength、[J-LeadLag] Edge Components (30s) が個別に用意されており、説明文でもそれぞれの役割が分けて書かれています。
J-LeadLag 側でいちばん大きかったのは、best_tau_sec を単独表示から外し、relation strength の一部として score / stability / pairs とセットで見せるようにしたことでした。service 側では on_tick() の中で、relation_snapshot() から pairs, best_tau_sec, score, stability_metric を取り出し、ready_ok と relation_weak を作ったうえで state / reason へ落としています。つまりロジック上でも relation の読みは、tau だけでなく score と stability、pairs を合わせて初めて成立しています。にもかかわらず、以前のパネルでは best_tau_sec だけが EV Context に同居していて、そこだけが少し浮いた値として見えていました。今回 exporter には obx_mmarb_j_leadlag_score, obx_mmarb_j_leadlag_stability, obx_mmarb_j_leadlag_pairs, obx_mmarb_j_leadlag_best_tau_sec を追加し、Grafana 側でも [J-LeadLag] Relation Strength - Long/Short を分けて置くことで、「何秒遅れか」と「その遅れ仮説がどれくらい強いか」と「その強さが続いているか」と「母数は十分か」を一箇所で読めるようにしました。
pairs = float(relation.get("pairs", 0.0))
best_tau_sec = float(relation.get("best_tau_sec", 0.0))
score = float(relation.get("score", 0.0))
stability = float(relation.get("stability_metric", 0.0))
ready_ok = pairs >= float(self.leadlag_min_pairs) and best_tau_sec > 0.0
relation_weak = (
score < self.relation_min_score
or stability < self.relation_min_stability
)
もう一つ分けたかったのが、relation 側の話と future outcome 側の話です。J-LeadLag の判定ロジックは、quality → ready → relation → future facts の順で読んでいて、最終的な YES 条件は hit_30 >= yes_hit_rate_pct and delta_mean_30 > 0.0 and delta_latest_30 > 0.0 and edge_30 のように future outcome 側の事実に依存しています。つまり score や best_tau_sec が relation の側だとすると、hit_rate_30s_pct, delta_mean_30s_bps, delta_latest_30s_bps は outcome の側です。ここが同じ EV Context に一枚で乗っていると、relation が弱いのか、edge が弱いのか、直近鮮度がないのかが少し見分けにくい。そこで今回は、LeadLag の Components を二つに分け、Samples / Hit Rate と Delta Mean / Delta Latest を separate にし、その外に Relation Strength を置く構成にしました。dashboard の説明文にも、delta_mean_30s_bps = 平均優位, delta_latest_30s_bps = 直近鮮度 と書いてあります。これによって少なくとも、「relation がある / ない」と「30秒主判定で方向優位がある / ない」を同じパネルの中で無理に読まなくて済むようになりました。
if hit_30 >= self.yes_hit_rate_pct and delta_mean_30 > 0.0 and delta_latest_30 > 0.0 and edge_30:
return "YES", "YES_LEADLAG_CONFIRMED"
J-Reversion 側では、少し事情が違います。J-Reversion はもともと J-LeadLag より先に置き直していたので、dashboard 側にも Horizon Sensitivity や Correlation-Conditioned Reversion、EV Context のような上位解釈寄りのパネルが先にありました。これらは観測器全体としては有用ですが、今回の目的である「J 判定器として一発で読む」には少し回り道になります。そこで今回は、J-Reversion についても state / reason / ready-quality / components を前に出し、expected move 相当の実数値を Components に集約しました。Prometheus 側には obx_mmarb_j_reversion_state_code, reason_code, ready_flag, quality_flag, samples_30s, hit_rate_30s_pct がすでにあり、expected move の実数値は新設せず、既存の pair future metrics を Grafana 上で流用する方針にしています。つまり、いきなり exporter を増やすより、今ある reversion facts を J 判定の読解へ寄せて再配置したという形です。
ここで意識したのは、state / reason / ready-quality / components を「全部見る」のではなく、見る順番を固定できる形にすることでした。State パネルの役割は、「いま YES / HOLD / NO のどこにいるか」を知ることです。Reason パネルの役割は、「なぜそこにいるのか」を知ることです。Ready / Quality は「この判定をそもそも読んでよいか」の前提確認です。Components は、その判定を支えている最低限の事実、つまり mature sample 数、hit rate、delta のような実数値を確認するための場所です。J-LeadLag に Relation Strength を独立で追加したのは、LeadLag に限っては relation の時間差診断が future outcome と別レイヤーにあるからです。逆に言えば、今回のパネル再設計は、単にレイアウトをいじったのではなく、J 判定器が内部で読んでいるレイヤーをそのまま人間向けの読解順へ写し直したという意味があります。
実際、service 側でも LEADLAG_DIAG を受けるたびに update_multi_market_leadlag_diag(...) で signal engine 診断を更新し、その後 forward tracker が future facts を積み、最後に _update_j_leadlag() が state / reason / ready / quality / 30s facts / relation values を exporter へ渡しています。つまり今回の Grafana 改修は、service 内部で既に存在しているこのレイヤー構造を、そのままパネルへ落とし直しただけでもあります。これをやったことで、J-LeadLag の state=HOLD を見た時に、「quality が悪いのか」「ready が足りないのか」「relation が弱いのか」「30秒 edge が弱いのか」を、少なくとも別々の場所で追えるようになりました。前のように EV Context 一枚に hit rate / delta / best_tau が同居している状態より、かなり素直です。
パネルを責務ごとに分けたことで見えてきたのは、情報を増やすこと自体は必ずしも読解力を上げない、という当たり前の事実でした。たとえば以前の J-LeadLag でも、30秒 hit rate と latest delta と best_tau は一応同じ画面にありました。ですが、それぞれの値が relation の話なのか、future outcome の話なのか、足元の鮮度なのかが頭の中で混ざっていると、判断器としてはむしろ重くなります。今回の分割でやったのは、数値を減らすというより、その数値がどのレイヤーの事実なのかを固定したことでした。観測器としての現在地を正しく言うなら、今回のパネル再設計でいきなり構造が見えたわけではありません。ただ、少なくとも「どこで止まっているのか」「何を次に見ればいいのか」は前よりかなり追いやすくなりました。J 系統を判定機として扱うなら、まず必要なのはこの読み順の固定だったと思っています。
4. 実装変更②:reason_code を数値から言葉へ直し、判定機としての読解コストを下げた

今回の改修で、見た目以上に効いたのが reason_code の可読化でした。前段で State / Reason / Ready-Quality / Components / Relation Strength に責務を分けたことで、J-Reversion / J-LeadLag の「どこを見るべきか」はかなり整理されました。ただ、それでも Reason パネルに 202 や 301 のような数値だけが出ている状態だと、実際にはその場でまだ一段翻訳が必要です。しかも J 系統は、state を見るだけではなく「なぜ HOLD なのか」「NO の主因は relation なのか edge なのか sample なのか」を reason で読む設計になっています。Prometheus exporter 側にも、J-Reversion と J-LeadLag の reason_code は state や ready / quality と並んで専用 Gauge として定義されていて、もともと reason は判定器の一部として扱う前提でした。
obx_mmarb_j_reversion_reason_code = Gauge(
"obx_mmarb_j_reversion_reason_code",
"Multi-market probe J-Reversion reason code (see exporter mapping table)",
_MMARB_J_REVERSION_LABELS,
)
...
obx_mmarb_j_leadlag_reason_code = Gauge(
"obx_mmarb_j_leadlag_reason_code",
"Multi-market probe J-LeadLag reason code (see exporter mapping table)",
_MMARB_J_LEADLAG_LABELS,
)
問題は、その「see exporter mapping table」の先が、人間の読解コストとしてはまだ高かったことです。たとえば J-LeadLag の _judge_direction() は、quality が悪ければ HOLD_QUALITY_ISSUE、ready が足りなければ HOLD_NOT_READY、30秒の sample が足りなければ HOLD_LOW_SAMPLE を返しますし、その先で relation が弱い場合も HOLD_RELATION_PENDING なのか NO_NO_RELATION なのかを分けています。さらに future outcome が弱ければ NO_NO_DIRECTIONAL_EDGE や NO_NO_LEADLAG_30S に落ちる。つまり J-LeadLag の state を正しく読むには、「いま HOLD なのは sample が足りないのか、relation がまだ弱いのか、あるいは quality が崩れているのか」を、その場で言葉として理解できないといけません。
if not quality_ok:
return "HOLD", "HOLD_QUALITY_ISSUE"
if not ready_ok:
return "HOLD", "HOLD_NOT_READY"samples_30 = float(facts_30s.get("samples_total", 0.0))
if samples_30 < float(self.min_samples_main):
return "HOLD", "HOLD_LOW_SAMPLE"...
if hit_30 >= self.yes_hit_rate_pct and delta_mean_30 > 0.0 and delta_latest_30 > 0.0 and edge_30:
return "YES", "YES_LEADLAG_CONFIRMED"if hit_30 < self.no_hit_rate_pct:
if hit_60 >= self.yes_hit_rate_pct and edge_60:
return "HOLD", "HOLD_ONLY_60S"
if hit_10 < self.no_hit_rate_pct and hit_60 < self.no_hit_rate_pct and (not edge_any):
return "NO", "NO_NO_LEADLAG_ANY_HORIZON"
if not edge_30:
return "NO", "NO_NO_DIRECTIONAL_EDGE"
return "NO", "NO_NO_LEADLAG_30S"
J-Reversion も同じです。こちらは quality → ready → relation weak pending/persistent → distortion events → hit_rate / edge の順で判定していて、reason には HOLD_LOW_SAMPLE、HOLD_ONLY_60S、NO_NO_RELATION、NO_NO_DISTORTION、NO_NO_DIRECTIONAL_EDGE、NO_NO_REVERSION_30S、NO_NO_REVERSION_ANY_HORIZON、YES_REVERSION_CONFIRMED といったラベルが返ってきます。つまり J-Reversion の reason は、単なる補足ではなく、「いまどの判定段で止まっているか」を示すデバッグ兼読解用の出力です。これが数値 code に圧縮されたままだと、state を眺めながら毎回頭の中で 202 = HOLD_LOW_SAMPLE のような逆引きをすることになり、判定機としてかなり重い。
if not quality_ok:
return "HOLD", "HOLD_QUALITY_ISSUE"
if not ready_ok:
return "HOLD", "HOLD_NOT_READY"samples_30 = float(facts_30s.get("samples_total", 0.0))
if samples_30 < float(self.min_samples_main):
return "HOLD", "HOLD_LOW_SAMPLE"...
if relation_weak_persistent:
if directional_evidence_weak:
return "NO", "NO_NO_RELATION"
return "HOLD", "HOLD_NO_RELATION_PENDING"
if relation_weak_pending:
return "HOLD", "HOLD_NO_RELATION_PENDING"if total_distortion_events < float(self.min_distortion_events_total):
return "NO", "NO_NO_DISTORTION"if hit_30 >= self.yes_hit_rate_pct and edge_ok:
return "YES", "YES_REVERSION_CONFIRMED"
そこで今回は、Grafana 側の Reason (Last) パネルで reason_code を value mapping によって文字列ラベルへ変換 しました。方針としては、judge ロジック本体は一切触らず、状態遷移も発番ルールもそのままにして、表示だけを人間向けにする。dashboard の Reason パネルはもともと「direction別 reason_code の Last。state の根拠を即時確認する。」という役割で置いてありました。ここに数字だけを出すのではなく、実装上の reason 名そのもの、たとえば HOLD_LOW_SAMPLE や NO_NO_RELATION を直接出すようにしたわけです。これによって、Reason パネルはようやく「コード一覧」ではなく「いまの判定がどこで止まっているか」を示すものになりました。
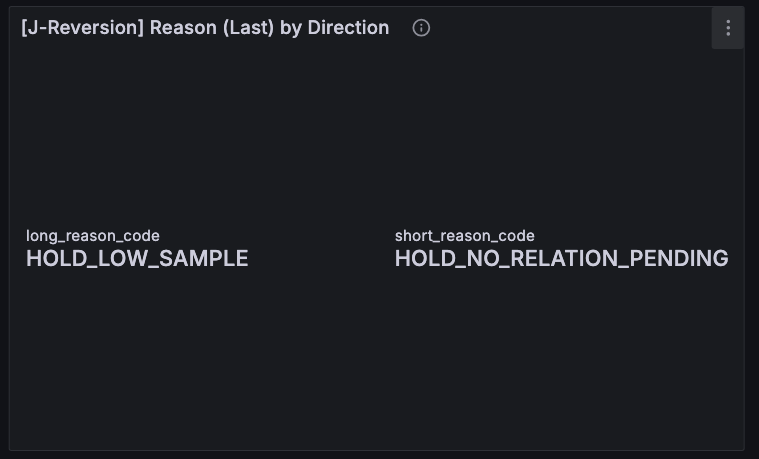
この変更の意味は、単に画面が見やすくなったという話ではありません。J 系統は、state と reason を別々に出している時点で、「YES / HOLD / NO の結果」と「そこに至った理由」は分けて読むべき、という設計思想を持っています。State だけを見ると、たとえば Reversion も LeadLag も「いま HOLD が多いな」で終わってしまいます。でも Reason がそのまま言葉で出るようになると、「HOLD が多い」のではなく「HOLD_LOW_SAMPLE が多いのか」「HOLD_NO_RELATION_PENDING が多いのか」「HOLD_QUALITY_ISSUE なのか」で読み方が変わります。前者なら sample 条件の話で、後者なら relation の閾値の話で、さらに quality なら観測器そのものの問題です。つまり可読化は UI の改善ではなく、state から一段下りて、ボトルネックを reason ベースで切り分けられるようにするための改修でした。
実際、今回の改修後は J-LeadLag の Reason を見た時に、「score が弱いのか」「30秒の edge が足りないのか」「sample がまだ成熟していないのか」を数値の逆引きなしで読めるようになりました。J-Reversion についても、「NO_NO_DIRECTIONAL_EDGE なのか」「NO_NO_REVERSION_30S なのか」「HOLD_ONLY_60S なのか」で、30秒 main の弱さと 60秒補助の残り方を区別しやすくなっています。これは今後のチューニングや signal routing を考えるうえでもかなり重要です。state の比率だけを見て「この J は厳しすぎる」と言うのと、reason を見て「厳しいのは quality ではなく relation で、しかも NO より HOLD が多い」と言うのとでは、次の手の打ち方がまったく変わるからです。
要するに今回の reason 可読化でやったのは、数値を言葉に置き換えただけではありません。J 判定器の出力を、「開発者しか読めない診断ログ」から「自分が毎回同じ順番で読める運用パネル」へ少し進めた、ということです。前章のパネル分割で state / reason / ready-quality / components の役割はかなり整理されましたが、Reason が数値のままではまだ最後の一段が残っていました。今回そこを言葉にしたことで、J-Reversion / J-LeadLag はようやく「見える」だけでなく「そのまま読める」ものに近づいたと思っています。
5. 実際に見えるようになったこと:構造の弱さと観測の問題を分けて読めるようになった
今回の改修でいちばん大きかったのは、J-Reversion / J-LeadLag の「答え」が見えたことではなく、何が原因で止まっているのかを分解して読めるようになったことでした。前の状態でも state や各種メトリクス自体は出ていましたが、relation の弱さ、future outcome の弱さ、観測品質の問題、sample 不足がパネル上で少し混ざっていて、結局「何となく HOLD が多い」「NO が多い」という雑な見方になりやすかった。今回、State / Reason / Ready-Quality / Components / Relation Strength に責務を分けたことで、少なくとも 観測機が壊れているのか、構造が弱いだけなのか を別々に追える状態には入りました。
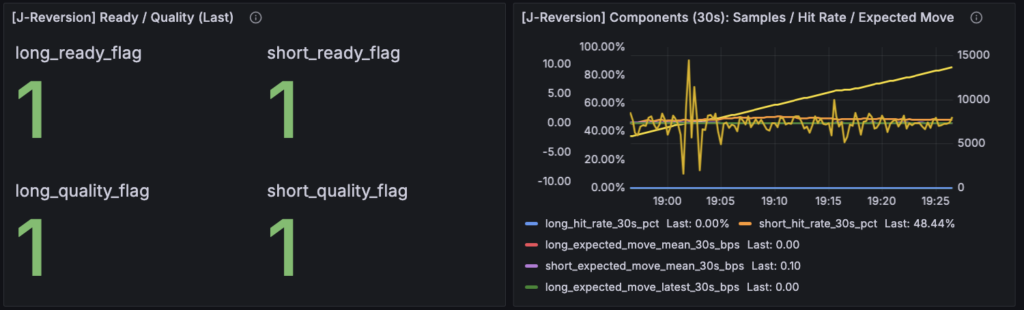
まず J-Reversion で分かりやすかったのは、ready / quality は立っているのに、expected move がかなり薄い ということです。今回のスクリーンショットでは、J-Reversion の state は long / short ともにほぼ HOLD、Reason は HOLD_LOW_SAMPLE などの読めるラベルになっていて、Ready / Quality は両方向とも 1 で立っています。一方で Components を見ると、expected move 相当として流用している delta 系の値はかなり小さく、short 側の mean でせいぜい 0.07bps 程度、latest も大きくありません。hit rate も short 側で 50%台、long 側は 0%近いタイミングがありました。つまり、少なくともこの時点の J-Reversion は「観測品質が悪いから HOLD」ではなく、観測はちゃんとしているが、30秒主判定で reversion edge が薄いので HOLD / NO に留まる と読めます。以前ならここで「State が弱い」で終わっていたところが、今は quality と components を切り分けて、「壊れているのではなく薄い」と言えるようになったわけです。
この読み方は、J-Reversion の judge ロジックとも整合しています。Reversion はまず quality_ok と ready_ok を確認し、そのあと samples_30、relation の弱さ、distortion events、最後に hit_30 と edge_ok を見て YES / HOLD / NO を返します。つまり ready / quality が立っているのに state が伸びないなら、理由はその先、すなわち sample・relation・edge のどこか にあるはずです。今回の Components と Reason を見れば、少なくとも「quality の問題ではない」「expected move が薄く、sample も十分ではない」までは自然に読めます。ここで重要なのは、J-Reversion の弱さを「観測機のせい」にせずに済むようになったことでした。
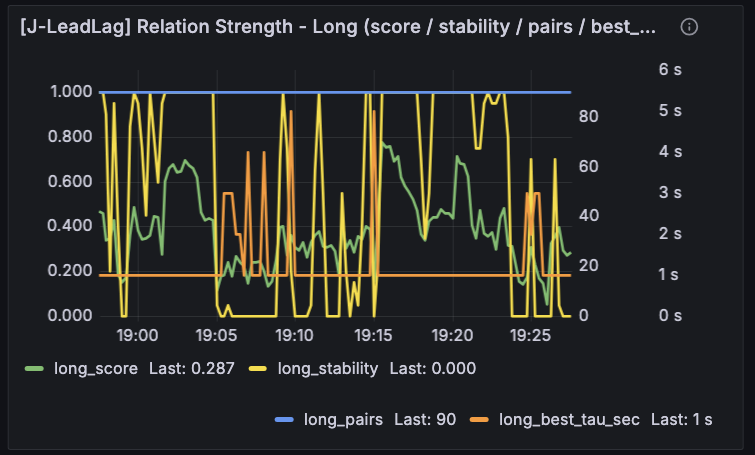
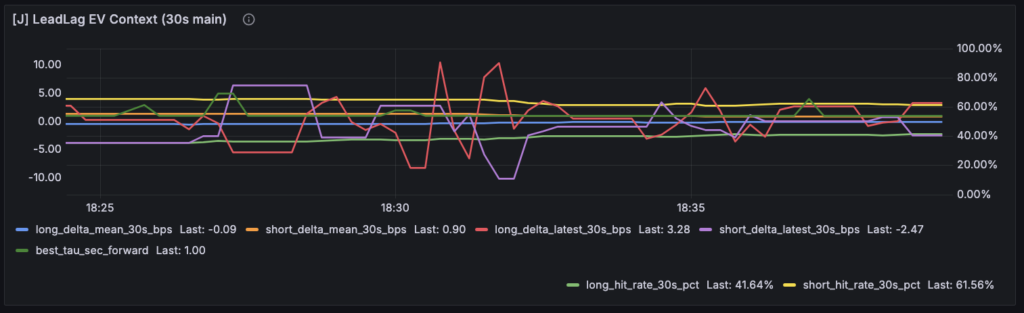
J-LeadLag では、もう少し面白いことが見えました。今回の Relation Strength パネルでは、long / short ともに pairs は十分あり、best_tau_sec も 4 秒前後が出ています。しかし同時に score は 0.16〜0.17 程度で低く、stability は 0 に張り付いていました。これはかなり示唆的で、遅れ時間の候補そのものは検出できているが、その relation は強くも安定的でもない という読みになります。以前のように best_tau_sec だけが EV Context に混ざっていると、この 4秒遅れ という数字だけが少し目立ってしまい、「何かありそうだ」と感じやすかったのですが、score / stability / pairs と並べたことで、少なくとも relation 側はまだ弱いと明言できるようになりました。best_tau_sec が出ることと score/stability が強いことは別、という当たり前の事実がパネル上でようやく崩れずに見えるようになったわけです。
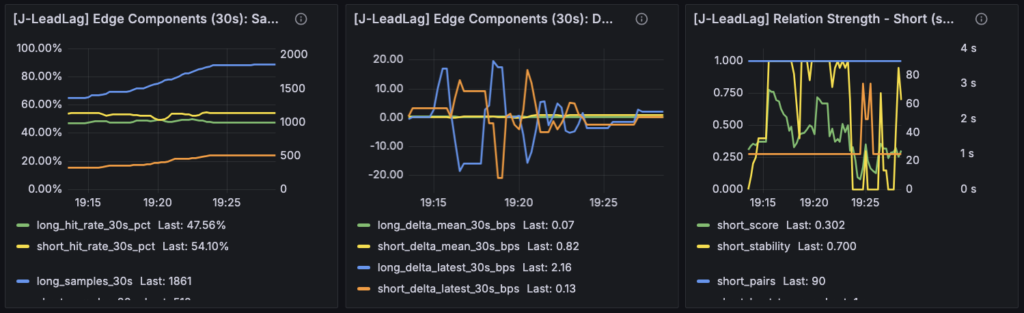
一方で J-LeadLag の Edge Components を見ると、short 側では hit_rate_30s_pct がそこそこ高く、delta_mean_30s_bps や delta_latest_30s_bps もプラスで推移している場面がありました。long 側は逆に hit rate も低く、delta もマイナスでした。つまり、future outcome 側だけを見ると short 方向に何か edge っぽいものは見えている ことになります。ただし Relation Strength は弱い。ここが今回、非常に重要な発見でした。前の状態だと「Lead-Lag の edge があるのかないのか」でまとめて考えがちでしたが、今は少なくとも
- relation としてはまだ弱い
- しかし short 側の future facts は多少良い
- だから「構造あり」とは言えないが、「何もない」とも言い切らない
という中間状態が見えます。J-LeadLag の judge が relation_weak のときに即 NO へ落とさず、30秒 facts が弱いときだけ NO_NO_RELATION、そうでなければ HOLD_RELATION_PENDING にしているのは、まさにこのためでした。relation は弱いが、future outcome 側に少し何か残っているなら HOLD に留める。そのロジックが、今回のパネルではかなり素直に読めるようになっています。
if relation_weak:
if hit_30 < self.no_hit_rate_pct and (not edge_30):
return "NO", "NO_NO_RELATION"
return "HOLD", "HOLD_RELATION_PENDING"
これによって見えるようになったのは、「J-LeadLag が弱い」のではなく、Lead-Lag を構成する relation と outcome のどちらが弱いのか です。今回のスクリーンショットの読みを短く言えば、
- short 側 outcome は少し良い
- でも relation strength は弱い
- だから YES ではなく HOLD が妥当
ということになります。これはかなり大きな違いでした。もし relation と edge を分けずに読んでいたら、「delta が正だから取れそう」「でも state は HOLD だから厳しすぎる」といった雑な印象で終わっていたはずです。今回の分離で、少なくとも なぜ HOLD に留まっているのか はかなり説明しやすくなりました。
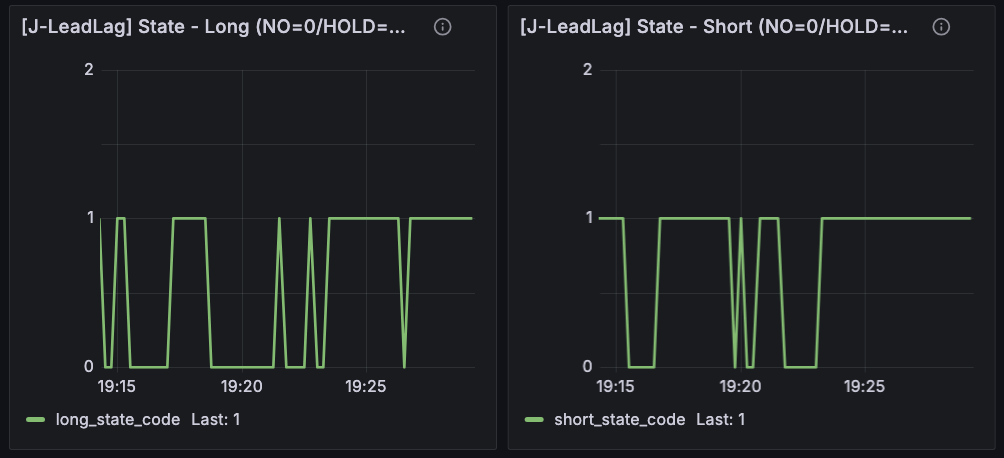
もう一つ見えたのは、long / short の非対称性 です。J-Reversion でも J-LeadLag でも、long と short を別々のパネルで見るようにしたことで、方向差がかなり素直に出ます。今回の例では J-LeadLag は明らかに short 側の方が edge components が良く、long 側は弱い。J-Reversion でも long 側は hit rate がほぼゼロの場面があり、short 側の方がまだマシという差が見えていました。これは観測器としてはかなり大事で、単一スコアや両方向混合のパネルにしていたら、この非対称性はかなり見えにくかったはずです。少なくとも現段階では、「この market pair に Reversion / LeadLag があるか」だけでなく、「どちら向きに弱く・どちら向きに少し残っているか」を別々に追えるようになっています。
今回の改修で見えるようになったことを、少し大きく言いすぎないようにまとめると、次の3点です。
第一に、観測品質が悪いのか、構造が弱いのかを分けて読めるようになった こと。
Ready / Quality が立っているのに state が弱いなら、原因は relation / samples / edge の側にあると分かる。
第二に、Lead-Lag の relation と future outcome を分けて読めるようになった こと。best_tau_sec が出ていても score/stability が弱ければ relation は弱いし、逆に delta や hit rate が少し良くても relation が弱ければ YES には上げない、という判断がしやすくなった。
第三に、方向別の非対称性がかなり素直に見えるようになった こと。
どちら向きが薄く、どちら向きに少し残っているのかを、混ぜずに追えるようになった。
逆に言えば、今回見えたのはまだ「構造そのもの」よりも、構造を読むためにどこで止まっているか の方です。これは一見地味ですが、観測器としてはかなり重要な段階だと思っています。YES を増やす前に、HOLD や NO がどこで発生しているのかを分けて読めるようにならないと、次のチューニングも signal routing も全部曖昧になるからです。今回の改修でようやく、その入口ができたというのが正直な実感です。
6. まだ見えていないものと次の一歩:signal routing の前に、J系統を運用可能な観測器へ整える
ここまでで、J-Reversion / J-LeadLag は少なくとも「存在しているかどうか分からないもの」ではなくなりました。state も reason も ready / quality も見える。LeadLag については relation strength と future outcome を分けて読める。Reversion についても expected move の薄さと観測品質を切り分けられる。つまり、観測器としての入口はかなり整ってきました。ただし、それはまだ 「運用できる観測器になった」 ことと同じではありません。今回の現在地を大きく言いすぎないなら、今あるのは「読めるようになり始めた判定器」であって、「そのまま執行へ流せる判定器」ではない、というのが正確だと思っています。
いちばん大きい未解決点は、signal routing をまだ固定していない ことです。今日の作業でも、J-Reversion / J-LeadLag を simulation candidate にどう昇格させるか、つまり YES かつ ready=1 かつ quality=1 の先にどの実数値を最低条件として置くかは、まだ仕様としては確定していません。読解メモの中では、Reversion なら expected move(bps) + ready + quality + samples、LeadLag ならそれに best_tau_sec を加え、hit_rate や delta_mean / delta_latest を補助確認として見る、というところまで整理しました。ただ、これはまだ「自分がどう読みたいか」の段階であって、コードの中で simulation_candidate_reversion や simulation_candidate_leadlag を出す最小 routing 仕様としては固定していません。つまり今の J 系統は、判定としてはかなり整理された一方で、その判定を“次の行動”へどう繋ぐかはまだ未定 です。
この未定は、怠けて先延ばしにしているというより、順番の問題だと思っています。今回先にやったのは、「何を見ているのか」「どこで止まっているのか」が読めるようにすることでした。もしこれが曖昧なまま signal routing を入れてしまうと、YES が少ないのは relation が弱いからなのか、edge が足りないからなのか、quality が悪いからなのかが分からないまま candidate signal だけが増えることになります。そうなると、後で EV を見に行っても、どこが壊れていたのかを遡るのが難しい。だから今の段階では、routing を急ぐより先に J 系統を「どこで何が足りずに止まるか」が分かる観測器へ整えること の方が優先でした。今回のパネル再設計と reason 可読化は、そのための地ならしだったと思っています。
まだ見えていないものも、かなりはっきりしています。まず、reason の分布 はまだ十分に読めていません。今回ようやく HOLD_LOW_SAMPLE や HOLD_RELATION_PENDING のようなラベルをその場で読めるようになりましたが、それはあくまで単発のスクリーンショットや短時間の観察に対してです。次に本当に見たいのは、
- どの reason が時系列でどれくらい多いのか
- どの reason が long / short のどちらに偏るのか
- 時間帯や market regime によって、どの reason に詰まりやすいのか
です。state が HOLD に張り付いていると分かっただけでは不十分で、HOLD の主因が何か を reason 分布として見ないと、閾値調整をするにしても構造否定をするにしても、手の打ち方が決まりません。今は reason を読めるようになった入口まで来た、という段階です。
次に、J-Reversion の expected move と J 判定閾値の整合 もまだ少し気になります。今回の Reversion Components は、既存の pair future directional delta metrics を流用して組んでいます。これは最小差分としては妥当でしたが、State の判定は j_reversion_eval.threshold_bps を使っている一方、Grafana 側の expected move は dashboard 変数 $f_threshold_focus の pair metrics を参照しています。この threshold がズレていると、state は YES / HOLD / NO をある閾値で返しているのに、画面に出ている expected move は別閾値の集計、ということが起こりえます。今回のスクショでは expected move 自体がかなり小さかったので大きな齟齬は目立ちませんでしたが、今後 signal routing や EV 検証へ進むなら、state の閾値と Components の実数値が同じ文脈を見ているか はどこかで合わせた方がよいはずです。
J-LeadLag 側でも、まだ見えていないものがあります。たとえば今回 best_tau_sec は relation strength とセットで読めるようになりましたが、tau の安定性そのもの はまだ見ていません。今は score と stability で「相関が強く継続しているか」は見ていますが、best_tau_sec 自体が時間的にどれだけ安定しているのか、たとえば 2秒・4秒・5秒と大きく揺れているのか、それとも特定帯でかなり固定的に出るのかまでは追っていません。前回の実装時にも、ここは intentionally 入れていない部分でした。いまはまだ relation と future outcome をつなぐ骨格を作るのが先で、tau stability まで広げるとまた一段抽象度が上がるからです。ただ、長い目で見れば、Lead-Lag を本当に「構造」と呼ぶなら、tau の安定性はどこかで見たくなるはずです。
それと同じくらい重要なのが、この J 系統を別市場へ持っていけるか という視点です。今回作っているのは bf_fx × binance_perp を対象にした multi_market_probe の J 層ですが、長い目で見るとここでやっていることは特定市場専用の小細工ではなく、観測器の雛形を作ることに近いです。Reversion なら relation / distortion / future outcome をどう読み、LeadLag なら relation strength / future facts / state / reason をどう分けるか。この型がしっかりしていれば、来週以降に別 market pair へ横展開する時にも、そのまま再利用できる可能性があります。逆に、いまの段階で J 系統が自分でも読みにくいままだと、この横展開はかなり危険です。市場を増やすたびに「何を見ているのか」をまた一から解釈し直すことになってしまうからです。
その意味で、次の一歩は新しい判定器を増やすことではなく、J 系統を“運用可能な観測器”へ寄せること だと思っています。ここで言う運用可能とは、単に Grafana に値が出ることではありません。
- state を見る
- reason を見る
- ready / quality を確認する
- 最低限の components を確認する
- そこで simulation candidate に上げる / 上げないを決める
この読み順が、毎回ほぼ同じ形で回ることです。そこまで行けば、次に最小 signal routing 仕様を固定してもよいし、その candidate を使って執行を含めた EV 検証へ進めます。さらにその先には、観測器を一段昇格させて、シミュレーション・執行・シグナル生成までをつなぐエッジ検証システムへ発展させる構想もあります。いまはまだそこまで行っていませんが、少なくとも今回の整備で、「J 系統の出力をそのまま人間が読めること」はかなり前提として近づきました。長い目で見ると、これは単なる Grafana 改修ではなく、観測機を将来の執行系へ接続するための地盤固め だったのだと思っています。