
こんにちは。ぼっちboterよだかです。
今回は、最小構成で新しい lead-lag 観測機を立ち上げ、起動導線や監視系を整理し、ダッシュボードの NoData を潰しながら観測の器を整えていったのですが、そこで見えてきたのは「観測機が壊れている」のではなく、指定していた lead source の性質が 24 時間稼働の live 観測と噛み合っていなかったという事実でした。
切り分けを進める中で、ETF を lead に置いたままでは何が確認できて何が確認できないのか、一時的に 24H の BTC/USD 系 source へ差し替えると何が見えるのか、そして新しい観測機の骨格自体は本当に動いているのか、という点を順に潰していきました。
結果として、event が出ていなかったのはエッジが無いからではなく、lead 入力が成立していなかったからだと確認できましたし、一時差し替えによって event detector・evaluation・metrics・dashboard までの end-to-end も無事通せました。
この記事では、実装を始めたところから現時点までの流れを、単なる作業ログではなく、どう考えて何を確認し、どこで方針を修正したのかが追える形でまとめます。今回の進捗は、「新しい観測機を作った」というだけでなく、その観測機が成立する条件と、lead source に求める適性を実地で確かめたという意味でもかなり大きかったと感じています。
-

-
🛠️開発記録#506(2026/4/8)Binanceリードラグ研究DAY4「研究の再設計 ― 構造が見えても勝てない理由から、次に掘る時間軸を決めるまで」
続きを見る
まずは新しい観測機を最小構成で立ち上げた
今回の開発では、まず最初に「何を作るのか」をかなり意識的に絞るところから始めました。
というのも、ここまでのリードラグ研究を振り返ると、構造の観測や判断そのものはある程度できるようになってきた一方で、そこから先の実装が少しでも膨らむと、すぐに「何を検証したい観測機なのか」が曖昧になりやすかったからです。
とくに今回は、以前まで見ていた短い時間軸の構造から一度距離を取り、個人 botter が現実に回収できる時間幅に lead-lag を置き直すという研究の再設計をした直後でした。
そのため、いきなり多機能な観測機を作り込むよりも、まずは
- lead source から必要な価格系列を取り込めるか
- event detector が発火できるか
- その後の評価ロジックまで流れるか
- ダッシュボードやログに判断根拠がきちんと残るか
という、研究用 probe として最低限必要な配線が通っているかを確認することを優先しました。
今回の実装目的は、かなりはっきりしています。
Bitcoin に比較的近い非クリプト source が、Binance Japan BTC/JPY に対して、個人 botter でも執行後に回収可能な数分帯の遅れを持つかを検証するための、新しい観測機の最小骨格を作ることです。
ここで大事なのは、売買シグナルや実執行をいきなり作ることではありません。
まずは、lead source → event 判定 → lag 側評価 → コスト考慮 → 可視化 までの一連の流れが、研究用の器として正しく動くかどうかを確かめることでした。
この前提に立つと、今回やるべきことも自然に決まってきます。
盛るべきではないのです。
たとえば、最初から複数 source を同時に入れたり、イベント定義を複雑化したり、補助レイヤーとして FOMC や CPI や雇用統計まで足したりすると、一見それらしくは見えても、「何が原因で動いたのか」「どこが詰まっているのか」が一気に分からなくなります。
それは、今の段階では明らかに得策ではありませんでした。
今回必要だったのは、研究対象を広げることではなく、新しい設計思想に沿った最小構成で観測機を一本立ちさせることだったからです。
そのため、実装の方針もかなり意識して絞りました。
まず、旧ベンチマークとして動かしていた Binance 先物ベースの観測機は、常時運用の主役から外しました。
これは過去の取り組みが無意味だったということではありません。むしろ逆で、あの観測機からは「短期では構造が見えても、個人が回収するには厳しい」という重要な否定結果を得ています。
ただし、今回の主目的はそのベンチマークを並走させて比較することではなく、新しい probe が単独で成立するかを確認することでした。
そのため、起動導線や監視ポートを増やして複数系統を常時並走させる構成は、今の目的に対して少し過剰だと判断しました。
実際、このあたりは運用上の分かりやすさにも直結します。
研究用の観測機は、動いていることそれ自体よりも、「いまどのシステムが動いていて、何を観測していて、どのダッシュボードを見ればよいのか」が明快であることの方が大切です。
とくに今回のように、起動導線や Grafana / Prometheus のポート、既存 benchmark との関係が曖昧なまま開発を進めると、それだけで検証が濁ります。
なので今回は、まず root の make 導線を新システム側へ寄せること、監視系の入口を整理すること、旧 benchmark は保存しつつも主運用から退かせることを重視しました。
観測機の中身についても、最初からかなりシンプルに置いています。
event 定義は、初期版では 300 秒 return shock のみです。
方向はその符号で持ち、連続方向変化のような別定義は今回入れていません。
評価 horizon も、30s / 60s / 180s / 300s / 900s に固定しました。
ここで 300 秒 return shock を採用したのは、60 秒程度の短い窓では、以前から見てきたように「見えても取れない」世界に寄りすぎる一方で、いきなり 900 秒をイベント検知窓にしてしまうと、今度は event とその後の追随を区別しにくくなるからです。
5 分程度のショックを起点に、その後 30 秒〜15 分の範囲で何が残るかを見る、という設計は、今の研究テーマに対してかなり自然だと考えました。
また、評価の考え方も今回かなり明確にしました。
ここで見たいのは単純な予測精度ではなく、執行コストを跨いだあとでもなお残る動きがあるかです。
そのため、ログやメトリクスでは gross、fee-adjusted、research-net を分けて扱う前提で進めています。
まだ実執行に直結させる段階ではないので、スリッページは research 用の固定仮定を置いていますが、それでも最初から「コスト込みでどう見えるか」を分けて残すことは重要だと考えました。
ここを曖昧にすると、また「当たる構造」と「実際に取れる構造」が混ざってしまうからです。
こうして見ると、今回の1本目の観測機は、見た目以上に目的が限定されたものです。
何でもできる観測機ではありませんし、今はまだそうあるべきでもないと思っています。
今回本当に作りたかったのは、新しい研究方針に沿った最小限の観測器でした。
まず lead source を受け取り、event を作り、lag 側の評価へ流し、その結果をログとダッシュボードで確認できる。
その流れさえ成立すれば、ようやく「この source は使えるのか」「この時間帯で研究可能なのか」という次の問いに進めます。
逆に言えば、そこが成立していないうちは、エッジの有無を語ること自体がまだ早いわけです。
今回の実装は、まさにその入口づくりでした。
最小構成で観測機を立ち上げる、というと一見地味に見えるかもしれません。
けれども、ここで設計思想と実装範囲を絞り、何を確認するための器なのかを明確にしたことは、後の判断をかなり楽にしてくれるはずです。
実際、このあと NoData を潰していく中で、「ダッシュボードの問題」なのか「series の問題」なのか「lead source の入力不成立なのか」を切り分けられたのも、最初に器をシンプルにしていたからこそでした。
起動導線と監視系を整理し、観測機の“器”を先に整えた
今回、最初に行った判断は、旧ベンチマークを常時運用の主役から外し、新しい観測機を主系として一本化することでした。
理由は明確です。
今回確認したかったのは、旧 benchmark と新 probe を並走させて比較することではなく、新しい設計思想で作った観測機が最小構成で正しく動くかどうかでした。
その段階でシステムが二本立てになっていると、起動対象、監視ポート、ログ、ダッシュボードの対応関係が分かりにくくなります。そうなると、何か問題が起きたときに、観測機の不具合なのか、起動導線の混乱なのか、監視系の参照先ミスなのかを切り分けにくくなります。
そこで実際に行ったのは、次の3点です。
まず、旧 benchmark は保存しつつ、root の標準起動対象から外しました。
今後は新システムを主運用対象にし、make start / stop / status が新しい観測機を対象にする形へ寄せました。
次に、ポートを増やさず、もともと使っていた監視ポートを新システム側へ引き継ぎました。
ポートを分けて共存させる構成自体は一般には自然ですが、今回はその必要性よりも、運用の単純さを優先しました。とくに外部 source を使う以上、二重起動による API リクエストの重複やレート制限の悪化は避けたかったからです。
最後に、Grafana と Prometheus の参照先を新システムに揃え、監視対象を一本化しました。
ここを曖昧にしたままだと、NoData が出たときに「本当に event がない」のか「監視先が違う」のかが分からなくなります。研究用の観測機では、この区別がつくことがとても重要です。
この段階でやったことは地味ですが、判断としてはかなり大きかったと思っています。
今回必要だったのは、機能を増やすことではなく、いま何が起動していて、どこを見れば状態が分かるのかを明確にすることでした。
そこを先に整えたことで、後の切り分けでは「lead source が悪いのか」「パネル式が悪いのか」「観測機自体が壊れているのか」を一つずつ見られる状態に持ち込めました。
ダッシュボードの NoData を潰しながら、何が見えていて何が見えていないかを切り分けた
次に行った判断は、NoData を「まだ何も起きていない」ではなく、「どこが詰まっているのかを示す情報」として扱うことでした。
理由は単純です。
この段階では、event が出ていない原因がまだ分かっていませんでした。
観測機の実装が壊れているのか、ダッシュボードの式がおかしいのか、lead source が入っていないのか、このどれかで必要な対応は大きく変わります。
ここを曖昧にしたまま threshold や source をいじると、問題の本体が見えなくなります。
実際に行ったことは、NoData の出方をパネルごとに分けて確認し、順番に潰していくことでした。
まず確認したのは、lag 側の観測が生きているかです。
BJ Spread / Estimated Cost は値が出ていたので、Binance Japan 側の観測とメトリクス配線は少なくとも動いていると判断できました。
この時点で、「観測機全体が死んでいる」という可能性は下がりました。
次に見たのは、event 系パネルがなぜ空なのかです。
Event Count、Median Time-to-Hit、Time-of-Day Split、Source Shock Size Distribution などが NoData のままだったので、ここでは二つの可能性がありました。
- event が本当に1件も出ていない
- event が出ていなくても 0 を返すべき series / panel が作られていない
この切り分けのために、series の初期化や常時計測化が入っていない箇所を修正しました。
つまり、「未発火だから 0」なのか「そもそも series が存在しないから NoData」なのかを分けられる状態にしたわけです。
この作業の結果、いくつかのパネルは NoData ではなく 0 表示になりました。
ここで分かったのは、少なくとも一部の問題は「event が出ていないこと」ではなく、表示側が未発火時の series を前提にしていなかったことだった、ということです。
ただし、それで終わりではありませんでした。
NoData が消えても、event 自体は依然として 0 のままでした。
つまりここで初めて、問題の中心はダッシュボードではなく、event を作る手前にあると絞れました。
そこで次に確認したのが、lead source が本当に入っているかです。
この確認では、quality flag、freshness、computable flag、event total といった値を見ました。
その結果、lead 側は quality が 0、freshness が異常に大きく、300 秒 return shock は computable になっていないことが分かりました。
要するに、event detector は「発火していない」のではなく、そもそも発火判定に必要な入力をもらえていなかったのです。
この切り分けでかなり大きかったのは、event=0 を「エッジなし」と誤読せずに済んだことでした。
もしここでダッシュボードだけ見て、「何も起きていないからダメそうだ」と判断していたら、それは明らかに早計でした。
実際には、lead 入力不成立で event detector が動けていなかっただけで、研究判定に入る前の段階で止まっていたからです。
ここまでで得た結論はかなり明確です。
NoData 問題の中心は、観測機全体の崩壊ではありませんでした。
lag 側は見えており、メトリクスも一部は動いていた。
問題は、lead source の品質不良と、その結果として 300 秒 return shock が未計算になっていたことでした。
この段階でようやく、次にやるべきことが整理できました。
必要だったのは、パネル追加でも threshold 調整でもなく、lead source を生きた系列として入力できる状態を作ることでした。
NoData を潰したこと自体が成果というより、NoData を通して「どこが壊れていて、どこは壊れていないのか」を見分けられたことが大きかったと思っています。
結局詰まっていたのは実装よりも lead source の入力不成立だった
ここまで切り分けて、次に行った判断は、問題の中心は観測機の実装ではなく、lead source の入力そのものにあるとみなすことでした。
理由は、確認した値がかなりはっきりしていたからです。
event は 0 のままでしたが、それだけではまだ何も言えません。
ただ、その内訳を見ていくと、lead 側の quality flag は 0、freshness は異常に大きく、300 秒 return shock は computable になっていませんでした。
つまり、event detector は「発火していない」のではなく、発火判定に必要な価格系列そのものを受け取れていなかったわけです。
ここで大事だったのは、未達と未計算を分けて考えることでした。
もし 300 秒 return shock が計算済みで、そのうえで threshold を超えないのであれば、それは「今回の source では event が弱い」という話になります。
しかし実際に起きていたのはそうではなく、return shock 自体が未計算でした。
この時点で、threshold や event 定義をいじるのは順番が違います。
まず先に直すべきなのは、lead 入力が event 判定に必要な品質で継続取得できる状態を作ることです。
実際に確認した内容も、その判断を裏づけていました。
ログには 429 が連続しており、lead source の freshness は数時間単位まで伸びていました。
replay 側でも lead の系列はほとんど入っておらず、lag 側だけが観測されている状態でした。
この状況では、lead-lag の評価どころか、lead 側の return すら作れません。
つまり、いま観測機で起きていたことは、「構造がない」でも「event が弱い」でもなく、lead 入力不成立による停止だった、ということです。
この時点で判断はかなり明確になりました。
ETF を lead に置いたこと自体は研究対象として間違っていないが、少なくとも今の 24H live 観測という運用形態には噛み合っていない、ということです。
ここは少し分けて考える必要があります。
ETF は、Bitcoin に比較的近い非クリプト source としては現状妥当です。
ただし、取引時間に強く依存する以上、JST 昼間を含む 24 時間連続観測では stale になってしまいます。
そこに取得元の制限や timeout まで重なると、観測機の入力としてはかなり不安定になります。
その結果として、今回のように「研究判定以前の段階で止まる」ということが起きます。
この状況を受けて、実際に行ったことはシンプルでした。
ETF lead をそのまま抱えたまま観測機の中身をいじるのではなく、一時的に 24H の BTC/USD 系連続価格 source へ差し替えて、観測機の end-to-end を確認することにしました。
ここでの狙いは、研究本命の source を変えることではありません。
観測機の骨格が本当に動いているのか、それとも実装のどこかが壊れているのかを確かめることです。
もし 24H で安定して取れる source に差し替えても event が出ないなら、問題は実装側にある可能性が高い。
逆に、そこで quality が立ち、computable になり、event が発火するなら、問題は source 側にあったと判断できます。
この切り分けができれば十分でした。
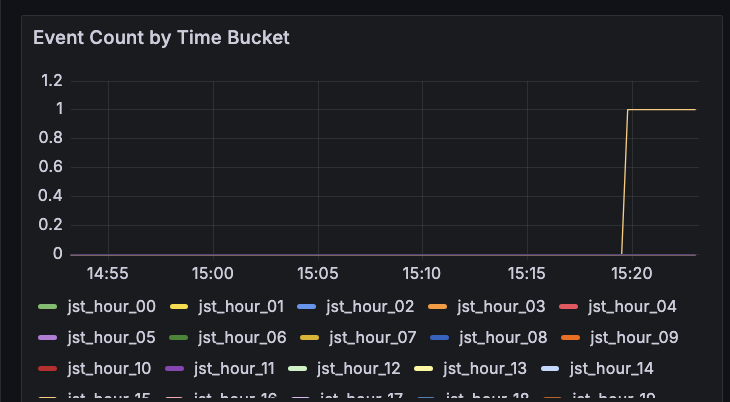
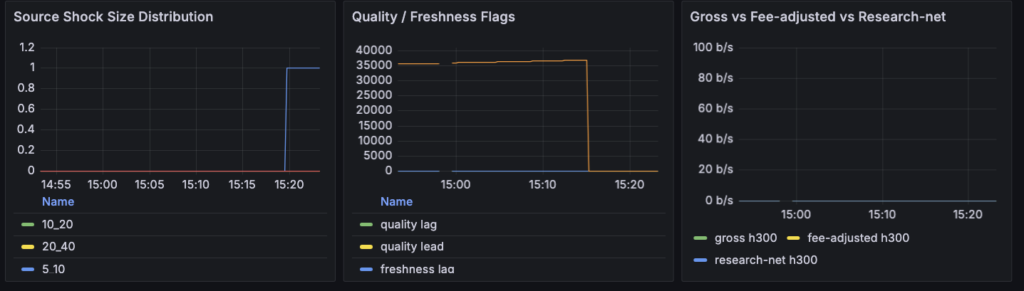
結果として、この temporary source では
- lead quality が 1
- 300 秒 return shock が computable
- event が実際に発火
まで確認できました。
つまり、観測機の骨格そのものは動いていたわけです。
event detector、evaluation、metrics、dashboard の end-to-end は成立しており、詰まっていたのは設計や実装の本体ではなく、元の lead source が 24H live の用途に合っていなかったことでした。
この確認はかなり大きかったです。
少なくとも、「観測機が動いていないから研究が進まない」のではないことが分かりました。
観測機は動いていて、問題は入力の側にあった。
ここが切れたことで、次にやるべきことも整理できました。
今後必要なのは、event 定義を増やすことでも、メトリクスを増やすことでもなく、lead source をどういう役割で使うかを正しく定義し直すことです。
つまり今回の結論は、かなりはっきりしています。
詰まっていたのは実装ではなく lead 入力だった。
そして、ETF は研究対象としては妥当でも、24H live lead としては不適切だった。
この2点が切れたことで、観測機の完成度と source の適性を混同せずに、次の判断へ進める状態になりました。
ETF は研究対象としては残しつつ、24H live lead としては一旦外して考えることにした
ここで行った判断は、ETF を完全に捨てるのではなく、少なくとも 24H の live 観測機における主 lead source からは一旦外して考えるというものでした。
理由は明確です。
ここまでの切り分けで分かったのは、event が出ない原因が観測機の実装不備ではなく、ETF lead の入力不成立にあるということでした。
実際には、lead 側の quality は立たず、freshness は大きく、300 秒 return shock は未計算のまま止まっていました。
この状態では、ETF を使って「構造があるか」「エッジがあるか」を議論する以前に、観測機の前提条件を満たしていないことになります。
ただし、ここでそのまま「ETF はダメだった」と結論づけるのは早いとも感じました。
今回確認できたのは、あくまで いまの運用条件、つまり JST 昼間を含む 24H 稼働型の live 観測機に対して、ETF をそのまま lead に置くと入力が成立しにくい、ということです。
これは source の価値そのものというより、source の性質と観測モードの相性の問題として読む方が自然でした。
そこで、ETF については評価を二段に分けることにしました。
ひとつ目は、研究対象候補として残すかどうかです。
この点については、現時点ではまだ残しておく方が妥当だと考えています。
ETF は、非クリプト取引所にある Bitcoin 近接 source として見たときには、依然として筋の良い候補です。
少なくとも今回の時点では、「lead としての意味がない」とまでは言えません。
まだ観測条件を揃えたうえで評価し直していない以上、研究対象から外す理由は不足しています。
ふたつ目は、24H live lead の主役として使うかどうかです。
こちらについては、一旦外して考えるのが自然だと判断しました。
今回の問題はまさにここで起きていて、24H の連続観測を前提にすると、ETF は stale になりやすく、event detector を動かす前提を満たしにくい。
それなら、少なくとも現段階では、ETF を 24H live source として抱えたまま観測機の中身を詰めるより、役割を分け直した方がよいです。
この判断を踏まえて、実際には ETF の扱いを次のように整理しました。
- 24H live lead の主役としては一旦保留
- 取引時間帯限定の観測対象として残す
- 必要なら replay / historical 前提の source として評価する
- 観測機の疎通確認とは切り離して扱う
要するに、ETF を捨てたのではなく、置き場所を変えたということです。
今までは「新しい観測機の最初の lead source」としてそのまま差し込んでいましたが、それだと source の性質に観測モードが引っ張られすぎます。
ここを整理して、ETF は ETF に合った時間帯や観測条件で見る対象として残し、24H で観測機を確認したいときは別の source を使う。この形に分けた方が、今後の研究はかなり進めやすくなると判断しました。
この判断には、研究を散らさないという意味もあります。
もしここで「ETF はダメそうだから捨てる」としてしまうと、今度はまた別の source を探す話にすぐ飛んでしまいます。
逆に「ETF が本命だから無理にでも 24H で回す」とすると、観測機の検証と source の適性評価が混ざってしまいます。
どちらも、今回やりたかったことからは少しズレます。
今必要だったのは、source の評価と観測機の成立確認を分けることでした。
その意味で、ETF を「研究対象候補としては残すが、24H live の主役からは外す」という整理は、かなりちょうどよかったと思っています。
現時点での立場を一言で言うと、こうなります。
ETF はまだ研究対象候補である。
ただし、24H 稼働型の live 観測機にそのまま差し込むのは一旦やめる。
ここまではかなりはっきりしました。
そのうえで、本当に見る価値があるかどうかは、取引時間帯や replay 条件であらためて観測して決める。
今回の整理は、そういう位置づけです。
一時的に 24H の BTC/USD 系 source へ差し替え、観測機の end-to-end を確認した
ETF を 24H live lead の主役から一旦外して考えることにした以上、次に必要だったのは、観測機そのものが本当に動いているかを切り分けることでした。
そこで、一時的に 24H の BTC/USD 系連続価格 source へ差し替え、lead 入力が正常に入ったときに event detector・evaluation・metrics・dashboard が end-to-end で動くかを確認しました。
この検証で確認したかったのは、エッジの有無ではありません。
見たかったのは、もっと手前の部分です。
具体的には、
- lead 側の quality が立つか
- 300 秒 return shock が computable になるか
- event が実際に発火するか
の3点でした。
結果として、temporary source ではこの3つが通りました。
つまり、観測機の骨格そのものは動いており、これまで event=0 で止まっていた主因は、実装不備よりも lead source の入力不成立 にあったと整理できます。
この確認が取れたことで、ようやく観測機の問題と source の問題を分けて考えられるようになりました。
今回の temporary source は研究本命ではありませんが、観測機の疎通確認用としては十分に役割を果たしたと思っています。
今日の結論と、今後の扱いを整理した
ここまでの進捗を一言でまとめると、観測機は動く。詰まっていたのは lead source 側だったということです。
今回確認できたことは、かなりはっきりしています。
- 新しい観測機は最小構成で立ち上がった
- 起動導線と監視系を新システム側へ一本化できた
- NoData の原因を、表示側・series 側・lead 入力側に分けて切り分けられた
- ETF を lead に置いた場合、少なくとも今の 24H live 運用では入力不成立で止まりやすい
- temporary な 24H source では end-to-end が通ることを確認できた
この結果から、今後の扱いもかなり整理しやすくなりました。
まず、ETF はいったん研究対象候補として残します。
ただし、24H live lead の主役としては一旦外し、取引時間帯限定あるいは replay / historical 前提の対象として見直す方向で考えます。
ここは今回の時点では白黒を急がず、観測条件を揃えたうえで改めて判断するつもりです。
次に、temporary 24H source は疎通確認用として残します。
今後、観測機の挙動確認や smoke test が必要になったとき、同じ検証をすぐに再現できる状態にしておく方が実務的だからです。
そして、今回いちばん大きかったのは、「event が出ない = エッジがない」ではないと事実ベースで確認できたことでした。
実際には、lead 入力が成立していなければ event detector は動けませんし、その段階で研究判定をしてしまうのは明らかに早いです。
この切り分けができたことで、次に見るべきものもかなり絞られました。
今回の進捗は、派手な成果ではありません。
けれども、研究の土台としてはかなり重要だったと思っています。
観測機を通しながら、lead source の適性を切り分ける。
その結果、何が動いていて、何がまだ研究判定に入れる状態ではないのかをはっきりさせる。
今回はそのための一日でした。