
市場間トレードを考えるとき、つい「どの戦略を使うか」から考え始めてしまいがちです。歪み回帰なのか、リード/ラグなのか、それともヘッジなのか。ですが実際にボットを作りながら検証していくと、もう一つ手前の問題にぶつかることがあります。それは、「そもそも今の市場に、その戦略が成立する構造が存在しているのか」という問いです。
今回の開発では、その問いに答えるための観測bot「multi_market_probe」を作っています。このボットはトレードを実行するためのものではなく、市場間の状態を観測し、戦略が成立する可能性を判定するための研究装置です。bitFlyer FX を基準に複数の市場を同時に観測し、価格差(premium)、その継続時間(persistence)、一定時間後の結果(future outcome)といった指標を記録しながら、市場間の構造を分布として捉えようとしています。
開発を進める中で、ひとつ重要な設計判断が必要になりました。それは、市場の事実を観測するレイヤー(Forward層)と、その事実を戦略として解釈するレイヤー(Judgment層)を分離するということです。もしこの二つを混ぜてしまうと、観測された事実と、そこから導いた解釈が区別できなくなり、ボットの判断がブラックボックス化してしまいます。逆にレイヤーを分離しておけば、どこまでが市場の事実で、どこからが自分の解釈なのかを明確に保つことができます。
この記事では、現在開発している multi_market_probe の構造を例にしながら、Forward層とJudgment層をなぜ分けて設計したのか、そして実際のダッシュボードや指標を通して、その分離がどのように機能しているのかを整理してみます。まだプロトタイプ段階の観測器ではありますが、実際に動かしてみることで見えてきた技術的な課題や、指標をどこまで信頼できるのかといった点についても、開発ログとして率直に書いていきたいと思います。
1. Forward層とJudgment層を分けた理由
市場間観測botを作っていて、途中から強く意識するようになったことがあります。
それは、市場の事実を観測する処理と、その事実を戦略として解釈する処理を分けないと、ボット全体がすぐにブラックボックス化するということです。
たとえば、市場間の価格差(premium)やその継続時間(persistence)、一定条件の後に価格差がどう変化したか(future outcome)といったものは、できるだけそのまま記録したい観測値です。これは「市場で何が起きたか」に属する話です。
一方で、それを見て
- これは歪み回帰として使えそうか
- この市場は他市場に先行しているのか
- ヘッジ可能な価格差として十分か
と判断し始めた瞬間、それはもう観測ではなく解釈になります。
この二つは似ているようで、役割がまったく違います。
観測と解釈を同じレイヤーで処理すると、後からダッシュボードを見返したときに、「これは市場の事実なのか、それとも自分がそう読んだだけなのか」が分からなくなります。すると、メトリクスを見ているつもりで、実際には自分の仮説を再確認しているだけ、という危ない状態になりやすくなります。
そこで multi_market_probe では、まず市場間の状態をそのまま記録する Forward層 を置き、その上に戦略別の見方を載せる Judgment層 を分ける構造にしました。今回の記事では、この分離がなぜ必要だったのか、そして実際のメトリクスやダッシュボードの中でそれがどう表れているのかを整理していきます。
2. multi_market_probe の全体アーキテクチャ
multi_market_probe は、ひとことで言えば **「複数市場の状態を観測し、その関係をレイヤーごとに整理する装置」**です。
ただし、内部ではいきなり戦略判断まで進んでいるわけではありません。実装としては、できるだけ役割を分離した形で組んでいます。
大まかには、次のような流れです。
各市場のデータ取得
↓
価格・スプレッド・premium の計算
↓
Forward層の指標生成
↓
Judgment層の指標生成
↓
Prometheus / Grafana で可視化
今回のプロトタイプでは、主戦場である bitFlyer FX を基準市場として、他市場の価格や状態を並列に取得し、それらを同じ土俵で比較できる形に揃えています。ここで重要なのは、最初から「売買シグナル」を作るのではなく、まず 市場間で何が起きているのかを観測可能な形に正規化することです。
内部構造をざっくり分けると、現在の multi_market_probe は次の三層になっています。
1. Probe層
最下層にあるのが、各市場のデータを取得して整形する部分です。
ここでは各市場から bid / ask / mid / recv_lag といった基本的な情報を取り込み、基準市場と比較できる形に揃えます。
たとえば USD 建ての市場であれば、USDJPY を使って JPY に換算し、bitFlyer FX と直接比較できるようにします。また、データの鮮度や遅延も同時に記録し、「今見えている価格」がどれくらい信頼できるかも後段に渡しています。
この層の役割は、あくまで 生の市場データを比較可能な状態に整えることです。
まだここでは「使えるシグナルかどうか」は判断しません。
2. Forward層
次に、その整形済みデータから市場間の状態量を作るのが Forward層です。
ここで扱っているのは、たとえば次のようなものです。
- 市場間の価格差(premium)
- executable ベースの価格差
- premium がどれくらい継続しているか
- 一定条件のあと、一定時間後に premium がどう変化したか
この層でやっていることは、「市場で何が起きたか」をできるだけそのまま記録することです。
つまり、ここで生成されるのは 観測された事実に近い指標です。
たとえば premium が 20bps あった、30秒後に 3bps 縮んだ、一定時間同じ符号が続いた、といった情報は、まだ戦略判断ではありません。これは単に 市場間の状態の記述です。
3. Judgment層
その上に載るのが Judgment層です。
ここでは Forward層の指標をもとに、
- これは歪み回帰として見えるのか
- これは lead-lag の兆候として読めるのか
- これは hedge の観点で現実的なのか
といった、戦略ごとの見方に整理していきます。
この層では、すでに「市場の事実」そのものではなく、「その事実をどう読むか」が含まれます。
たとえば Reversion の強さや Lead-Lag のスコア、Hedge feasibility のような指標は、すべて市場の観測結果をもとにした解釈です。
ここで初めて、「トレード戦略として意味があるかもしれない」という話が出てきます。
この構造にしている理由は明確です。
もし Probe・Forward・Judgment を最初から一体化してしまうと、後からダッシュボードを見たときに
- これは市場で実際に起きたことなのか
- それとも自分がそう読んだだけなのか
が分からなくなります。
multi_market_probe では、この混線を避けるために
- Probe層でデータを揃え
- Forward層で事実を記録し
- Judgment層で解釈を乗せる
という順序を取っています。
現時点では、この三層構造そのものはかなり固まってきました。
つまり今の開発フェーズは、「観測器の枠組みを作る段階」から、「その中で生成される各層の指標が本当に意味を持っているかを検証する段階」へ移りつつあります。
次の章では、この中でも特に重要な Forward層で何をどう記録しているのかを、もう少し具体的に見ていきます。
3. Forward層で記録しているもの
multi_market_probe の設計で、最初に作ったのが Forward 層です。
ここは名前の通り、「市場で観測された状態をそのまま前に流すレイヤー」です。
重要なのは、この層では 戦略判断を行わないという点です。
Forward 層の役割は、「何が起きたか」をできるだけ加工せずに記録することです。
トレードボットを作っていると、つい
- これは歪み回帰として使えるのではないか
- これはリード/ラグのシグナルではないか
といった判断を早い段階で組み込みたくなります。しかし、その時点で戦略の仮説をロジックに混ぜてしまうと、後からデータを見返したときに 観測と解釈の区別がつかなくなります。
そこで multi_market_probe では、まず市場間の状態を Forward 層の指標として記録するところから始めています。
現在のプロトタイプで Forward 層が扱っている主な指標は、次の三つです。
- premium
- persistence
- future outcome
それぞれが何を意味しているのかを、順に見ていきます。
premium:市場間の価格差
Forward 層の基本になるのが **premium(市場間の価格差)**です。
ここでは、基準市場である bitFlyer FX の価格と、他市場の価格を比較し、その差を basis points(bps)で表現しています。
単純化すると、次のような計算です。
premium = (base_market_price - reference_market_price) / reference_market_price
ただし実際には、トレード可能性を考慮して executable な価格差も同時に計算しています。
つまり、
- mid価格ベースの差
- bid / ask を使った executable な差
の両方を記録しています。
これによって、「理論上の価格差」と「実際に執行可能な価格差」を区別して観測できます。
Forward 層では、この premium を時間とともに継続的に記録しています。
ここではまだ、「この差が大きいからエントリーする」といった判断は行いません。
単純に 市場間の価格差がどのように変化しているかを観測しているだけです。
persistence:価格差がどれくらい続くか
次に記録しているのが **persistence(継続時間)**です。
premium は瞬間的に発生するだけでなく、一定時間その状態が続くことがあります。
たとえば、
- premium が +20bps を超えた
- その状態が 10秒続いた
- あるいは 60秒続いた
といったケースです。
Forward 層では、この「同じ方向の premium がどれくらい続いているか」を秒単位で記録しています。
ここで重要なのは、persistence は「戦略のシグナル」ではないということです。
これはあくまで 市場状態の記述です。
たとえば、ある市場では
- premium が短時間で消える傾向がある
- premium が長時間残る傾向がある
といった違いがあります。
こうした特徴を把握するために、persistence を Forward 層の指標として残しています。
future outcome:条件の後に何が起きたか
Forward 層の中で、最も研究用途に近い指標が future outcomeです。
これは「ある条件が発生した後に、一定時間後の市場状態がどう変化したか」を記録する仕組みです。
具体的には、次のような手順で記録しています。
- premium が一定条件を満たした瞬間を **anchor(起点)**として記録する
- その時点の premium を保存する
- 一定時間後(現在は主に 30 秒後)の premium を測定する
- その差分を future outcome として保存する
図にすると、次のようなイメージです。
t0: premium >= threshold → anchor t0 + 30s: premium 再測定 ↓ future_delta = premium(t0+30s) - premium(t0)
ここで重要なのは、この処理が 未来を予測しているわけではないということです。
future outcome はあくまで
「この条件が発生したとき、その後どうなる傾向があるのか」
という 条件付きの結果分布を観測するためのものです。
たとえば、同じ条件が 100 回発生したときに、
- 60 回は premium が縮小する
- 40 回は premium が拡大する
といった統計が取れれば、初めて「この条件には回帰傾向があるかもしれない」と議論できます。
この段階では、まだ戦略は存在していません。
あるのは 観測された結果の分布だけです。
Forward 層の役割
ここまでの三つの指標をまとめると、Forward 層は次の役割を持っています。
市場データ ↓ premium(価格差) ↓ persistence(継続時間) ↓ future outcome(条件付き結果)
つまり、
- 市場間で何が起きているのか
- その状態がどれくらい続くのか
- その後どう変化するのか
という 観測事実を記録するレイヤーです。
この層ではまだ、
- Reversion が成立するか
- Lead-Lag が存在するか
- Hedge が可能か
といった判断は行いません。
それらはすべて Judgment 層の仕事です。
Forward 層でやるべきことはただ一つです。
それは 市場の状態を、できるだけ歪めずに記録することです。
次の章では、この Forward 層のデータをもとに、戦略ごとの見方を整理する Judgment 層について見ていきます。
4. future outcome をどう測っているか
Forward層の中で、最も「研究装置らしい」部分が future outcome の観測です。
premium や persistence が「現在の市場状態」を記録する指標だとすれば、future outcome は その状態の後に何が起きたかを記録する指標です。
ただしここでも重要なのは、future outcome が 未来を予測するロジックではないという点です。
あくまで、同じ条件が発生したときに「実際にはどのような結果が起きているのか」を後から統計として蓄積する仕組みです。
anchor(起点)を記録する
future outcome の観測は、まず anchor(起点)イベントを定義するところから始まります。
たとえば、
- premium が一定以上に広がった
- premium の符号が一定時間継続した
- 特定の市場間条件が成立した
といった瞬間を anchor として記録します。
この時点ではまだ何も判断していません。
ただ「この条件が発生した」という事実を記録するだけです。
図にすると、次のようなイメージになります。
t0: 条件成立(anchor) premium = +22bps
この時点では、将来の値は当然まだ分かりません。
Forward層では、この瞬間の市場状態をそのまま保存します。
一定時間後の状態を測定する
次に、anchor が発生してから 一定時間後の市場状態を測定します。
現在のプロトタイプでは、主に 30秒後の premium を観測しています。
t0: premium = +22bps t0 + 30s: premium = +15bps
この場合、future outcome は
future_delta = premium(t0 + 30s) - premium(t0)
= -7bps
になります。
つまり、この例では 30秒後に premium が縮小したという結果になります。
ここで重要なのは、この処理が
- 「30秒後に縮小するはずだ」と予測しているわけではない
- 単に「30秒後にどうなったか」を記録している
という点です。
結果を分布として蓄積する
future outcome を一度だけ観測しても意味はありません。
重要なのは、同じ条件が何度も発生したときの 結果の分布です。
たとえば、次のようなデータが蓄積されるとします。
条件: premium >= 20bps 観測回数: 100回 30秒後の結果 ・premium縮小: 63回 ・premium拡大: 37回 平均変化幅: -3.1bps
このとき初めて、
- この条件では premium が縮小する確率は約63%
- 平均すると約3bps程度縮む
といった 統計的な傾向が見えてきます。
この段階になって初めて、「歪み回帰として使える可能性があるかもしれない」と議論できます。
horizon(観測時間)の問題
future outcome を観測するうえで、もう一つ重要なのが **時間幅(horizon)**です。
現在のプロトタイプでは主に 30秒後を観測していますが、これはあくまで暫定設定です。
市場によっては、
- 10秒で収束する歪み
- 60秒程度続く歪み
- 数分かけて解消される歪み
といった異なる時間スケールが存在する可能性があります。
そのため、将来的には
- 30秒
- 60秒
- 180秒
といった複数の horizon を観測し、
どの時間幅で最も強い回帰傾向が現れるのか
を調べる必要があります。
この作業は、戦略設計の前段として非常に重要です。
もし観測時間を誤ると、本来存在する構造を見逃してしまう可能性があるからです。
future outcome は「条件付き結果」
ここまでの内容をまとめると、future outcome は
条件 ↓ 一定時間後の結果
を記録する仕組みです。
言い換えると、
P(結果 | 条件)
という 条件付き分布を観測しています。
この分布を十分なサンプル数で取得できれば、
- Reversion が成立しているのか
- それとも premium がそのまま持続するのか
- あるいは逆方向へ拡大するのか
といった市場構造を、仮説ではなく データとして確認できます。
Forward層の役割は、まさにこの「条件付き結果」をできるだけ歪めずに記録することです。
そして、この分布をどのように解釈し、戦略として利用するかを考えるのが、次に説明する Judgment層になります。
5. Judgment層で何を組み立てているか
Forward層では、市場間の状態をできるだけそのまま記録してきました。
premium、persistence、future outcome といった指標は、いずれも「市場で何が起きたか」を記述するためのものです。
しかし、それだけではトレード戦略にはなりません。
たとえば premium が +20bps だったとしても、それが
- 回帰のチャンスなのか
- 単なる構造的プレミアムなのか
- 別の市場の動きに遅れているだけなのか
といった意味づけは、まだ行われていないからです。
そこで multi_market_probe では、Forward層のデータをもとに Judgment層を構築しています。
Judgment層の役割は、観測された市場状態を 戦略ごとの視点で整理することです。
ここで重要なのは、Judgment層が 市場の事実を作るレイヤーではないという点です。
ここで行っているのは、Forward層の観測結果を「どう読むか」という解釈の整理です。
現在のプロトタイプでは、Judgment層は主に次の三つの戦略を念頭に置いて設計しています。
- 歪み回帰(Reversion)
- リード/ラグ(Lead-Lag)
- ヘッジ(Hedge)
それぞれの戦略が成立する条件は異なるため、Judgment層では 戦略ごとに別の指標を組み立てる形にしています。
Reversion(歪み回帰)
Reversionの視点では、主に次のような情報を組み合わせています。
- premium の大きさ
- premium の継続時間(persistence)
- future outcome の分布
Forward層のデータだけでは、
premium = +20bps
という事実しか分かりません。
Judgment層では、この情報に
- premium がどれくらいの頻度で発生するのか
- 一定時間後にどれくらいの確率で縮小するのか
- 平均的な変化幅はどれくらいか
といった統計情報を組み合わせます。
その結果として、
この条件では回帰傾向が強いのか
という解釈が初めて可能になります。
ここで作っているのは「回帰の可能性を表す指標」であり、
それ自体が売買シグナルではありません。
Lead-Lag(リード/ラグ)
Lead-Lagの視点では、市場間の時間差を観測します。
Forward層では、単純に
- 各市場の価格
- 各市場の変化
を記録しているだけです。
Judgment層ではそこから、
- どの市場が先に動くのか
- その関係がどれくらい安定しているのか
- 何秒程度の遅れで伝播するのか
といった統計的な関係を整理します。
たとえば、
Binanceが先に動く ↓ bitFlyerが数秒後に追随する
という構造が繰り返し観測されるなら、
それは Lead-Lag の関係が存在している可能性を示します。
ただし、ここでもまだ戦略判断は行いません。
Judgment層では
その関係がどの程度再現されているのか
を整理しているだけです。
Hedge(ヘッジ)
Hedgeの視点では、市場間の価格差そのものを評価します。
ヘッジ戦略では、
- 市場Aを買う
- 市場Bを売る
という価格差ポジションを作るため、重要になるのは次のような要素です。
- premium の大きさ
- premium の分布
- スプレッド
- 流動性
- 執行可能性
Judgment層では、Forward層のデータをもとに
この価格差はヘッジとして現実的か
という観点で整理します。
たとえば、
- データが安定しているか
- 執行可能な価格差が存在するか
- スリッページが許容範囲か
といった条件をまとめて評価します。
これによって、「ヘッジとして成立する可能性」を判断するための材料が揃います。
なぜ一つのスコアにまとめないのか
ここでよくある設計は、すべての指標をまとめて 一つのスコアを作る方法です。
たとえば、
総合スコア = Reversion + Lead-Lag + Hedge
のような形です。
しかし multi_market_probe では、あえてこの方法を採用していません。
理由はシンプルで、
それぞれの戦略は前提としている市場構造が違うからです。
たとえば、
- Reversion は価格差の回帰を前提にする
- Lead-Lag は市場間の時間差を前提にする
- Hedge は価格差の存在そのものを前提にする
これらを一つのスコアにまとめてしまうと、
「どの構造が働いているのか」が分からなくなります。
そのため現在のプロトタイプでは、
- Reversionの指標
- Lead-Lagの指標
- Hedgeの指標
を 独立した形で並べる設計にしています。
Judgment層は「解釈のレイヤー」
ここまでをまとめると、Judgment層が行っているのは次の作業です。
Forward層(事実) ↓ 戦略ごとの視点で整理 ↓ 解釈としての指標
つまり、
- premium が発生した
- premium が30秒後に縮小した
という事実を、
これは歪み回帰として読めるのか
という形に変換しているのがJudgment層です。
このレイヤーは、どうしても 設計者の仮説や解釈を含みます。
だからこそ、Forward層と混ぜてしまうと、観測データの意味が曖昧になります。
multi_market_probe では、この混線を避けるために
- Forward層で事実を記録し
- Judgment層で解釈を組み立てる
という構造を取っています。
次の章では、これらの指標を実際にどのように可視化しているのか、
Q / C / M / F / J ダッシュボード設計について整理していきます。
6. Q / C / M / F / J ダッシュボード設計
multi_market_probe を作る過程で、もう一つ意識して設計したのが ダッシュボードのレイヤ構造です。
観測器を作っていると、つい様々な指標を追加してしまい、結果として「何を見ればよいのか分からないダッシュボード」になりがちです。
特に今回のように、
- 複数市場
- 複数戦略
- 複数時間軸
を扱う場合、指標の数はすぐに増えてしまいます。
そこで multi_market_probe では、ダッシュボードを Q / C / M / F / J の五つのレイヤーに整理しました。
これは単なる見た目の分類ではなく、
市場の事実 → 統計 → 解釈
という情報の流れに対応しています。
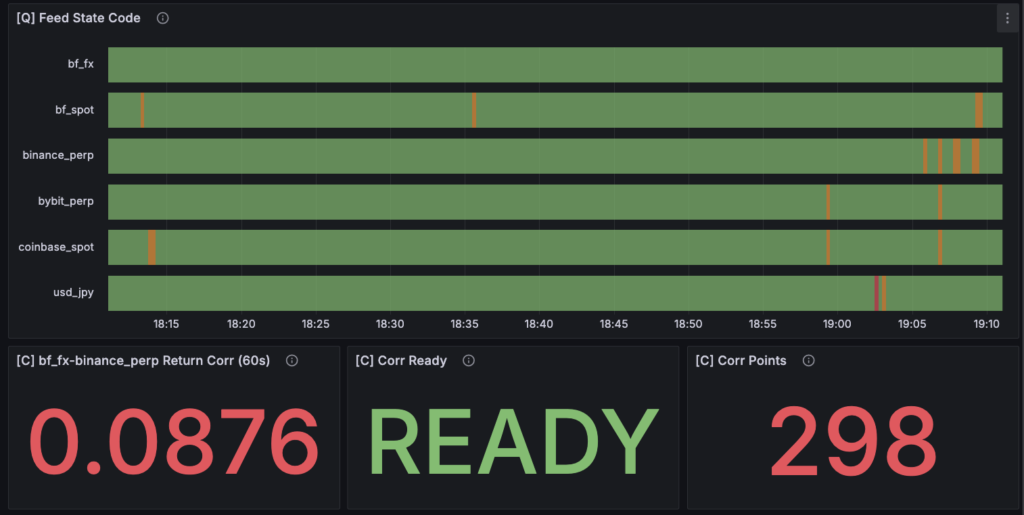
Q:Quality(データ品質)
最初に確認するのが Q(Quality)レイヤーです。
ここでは、
- feed state
- latency
- drop rate
- stale 状態
- データ更新間隔
といった データの健全性を監視しています。
アルゴリズムの研究では、ついシグナルや戦略に目が行きがちですが、
そもそも データが壊れていればすべての指標は意味を持ちません。
たとえば、
- 価格更新が止まっている
- データが遅延している
- 一部の市場だけ更新頻度が違う
といった状態では、市場間比較そのものが成立しなくなります。
そのため、ダッシュボードを見るときは必ず
Q → C → M → F → J
の順に確認するようにしています。
C:Correlation(市場間構造)
次に確認するのが C(Correlation)レイヤーです。
ここでは主に、
- 市場間リターンの相関
- サンプル数
- 相関計算が成立しているか(ready 状態)
といった 市場間の基本的な関係性を観測しています。
このレイヤーの目的は、
そもそも市場間に関係があるのか
を確認することです。
もし市場同士にほとんど相関がなければ、
- リード/ラグ
- 歪み回帰
といった戦略は成立しにくくなります。
つまり C レイヤーは、
市場間トレードの前提条件を確認するための層です。
M:Market State(市場状態)
次に来るのが M(Market State)レイヤーです。
ここでは主に、
- premium(市場間価格差)
- premium の幅
- premium の発生頻度
といった 市場間の状態を可視化しています。
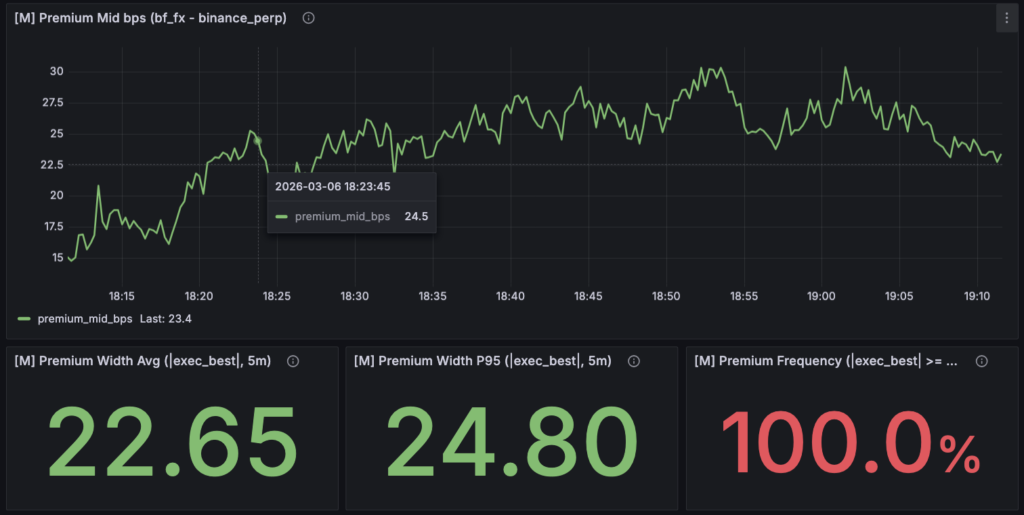
ここで重要なのは、
premium が存在するか
ではなく、
premium がどのような分布を持っているか
を見ることです。
たとえば、
- premium が常に 20bps 前後存在するのか
- まれに 50bps を超えるイベントとして現れるのか
では、戦略の前提が大きく変わります。
M レイヤーは、
市場間の価格差がどのような環境で発生しているのかを把握するための層です。
F:Forward Distribution(結果分布)
次が F(Forward)レイヤーです。
ここでは Forward 層で記録している
- persistence
- future outcome
- reversion hit rate
- premium の変化量
といった 結果の分布を観測します。

このレイヤーの目的は、
条件が発生したとき、その後どうなるか
を統計として把握することです。
たとえば、
- premium が 20bps 以上になったとき
- 30秒後に縮小する確率
- 平均変化幅
といったデータを蓄積します。
ここで初めて、
この条件には回帰傾向があるのか
といった議論が可能になります。
F レイヤーは、
市場構造を分布として理解するための層です。
J:Judgment(戦略解釈)
最後に来るのが J(Judgment)レイヤーです。
ここでは Forward 層のデータをもとに、
- Reversion strength
- Lead-Lag strength
- Hedge feasibility
といった 戦略ごとの解釈指標を組み立てています。
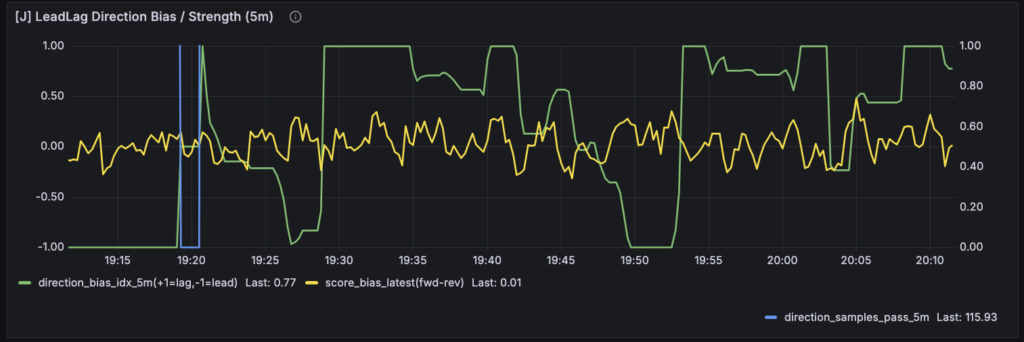
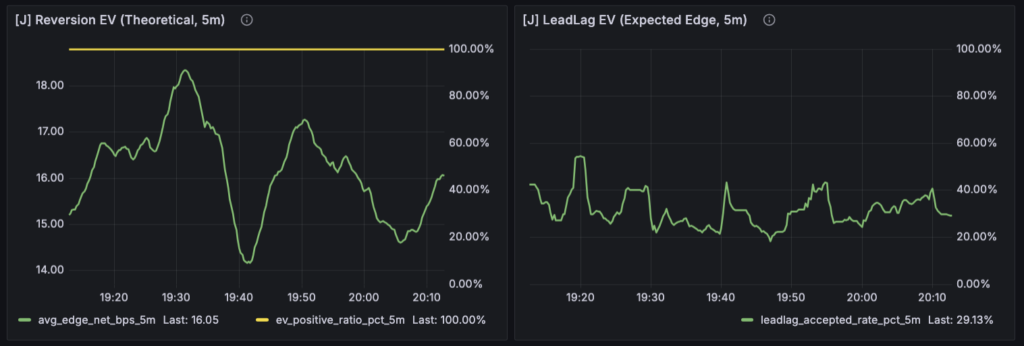
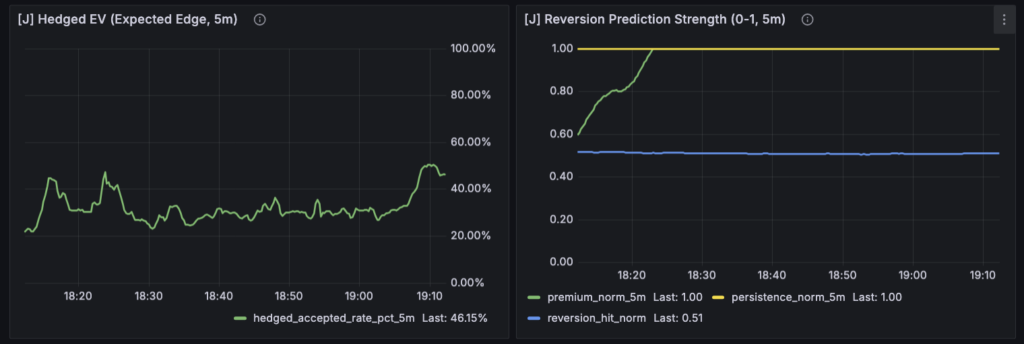
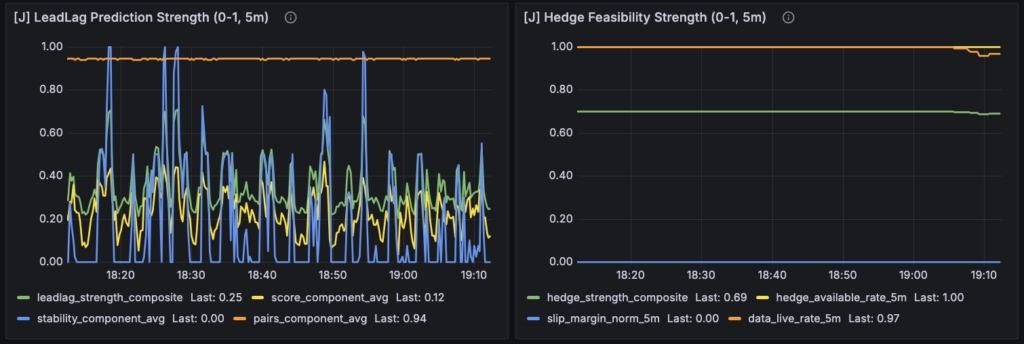
このレイヤーは、はっきり言って 市場の事実ではありません。
ここで表示される数値は、
- Forward 層の指標
- 市場状態
- 統計結果
をもとに組み立てた 解釈モデルです。
つまり、
F:市場で何が起きたか J:それをどう読むか
という関係になります。
なぜこの順序なのか
ダッシュボードをこの順序にしている理由は単純です。
Q:データは正常か ↓ C:市場同士に関係はあるか ↓ M:価格差は存在するか ↓ F:その結果はどう分布するか ↓ J:戦略として読めるか
この順序で見ないと、
解釈だけが先に進んでしまうからです。
たとえば、
- Q が壊れている
- C が成立していない
状態で J を見ても、それは単なるノイズになります。
multi_market_probe のダッシュボードは、
この順序で市場構造を理解できるように設計しています。
次の章では、このダッシュボードを実際に運用してみて見えてきた 問題点や課題について整理していきます。
7. 実際に動かして見えてきた問題
multi_market_probe のダッシュボードを一通り組み上げ、実際の市場データでしばらく動かしてみると、いくつか興味深いことが見えてきました。
それは「何かが壊れている」という種類の問題ではなく、むしろ 観測器が動き始めたことで初めて分かった問題です。
言い換えると、設計段階では見えなかった 市場の実態と指標設計のズレが見えてきた、という状態です。
ここでは、現時点で特に気になっている点をいくつか整理しておきます。
premium は「イベント」ではなく「背景状態」かもしれない
最初に気づいたのは、premium の発生頻度です。
ダッシュボードで premium の分布を確認すると、特定の市場ペアでは
- premium ≥ 10bps の発生率がほぼ常時
- premium の平均が 20bps 前後
といった状態が観測されました。
これは一見すると「大きな価格差が頻繁に発生している」と読めます。しかし実際には、その逆の可能性があります。
つまり、
premium はイベントではなく その市場ペアに固有の背景状態
である可能性です。
もし premium が常時 20bps 程度存在する市場構造であれば、「premium が広がったらエントリーする」という単純なルールは成立しません。
なぜなら、それは「異常」ではなく 通常状態だからです。
この問題は、Forward層の設計そのものが間違っているわけではありません。
むしろ、観測器を作ったことで 市場の構造的プレミアムが見えてきたとも言えます。
ただしこの場合、戦略設計は
premium の存在
ではなく、
premium が平均からどれだけ外れているか
を見る方向に変える必要があります。
threshold 設計が市場に合っていない可能性
もう一つ見えてきたのは、threshold の設定問題です。
たとえば Forward層では、
- premium ≥ 8bps
- premium ≥ 10bps
- premium ≥ 12bps
といった条件でイベントを観測しています。
しかし実際の分布を見ると、特定の市場では
premium ≥ 10bps 発生率 ≈ 100%
という状態になっていました。
この場合、threshold は 分別力を持たない指標になります。
つまり、「条件が成立した」というイベント自体に情報量がなくなってしまうわけです。
これは実装ミスというより、単純に パラメータが市場の実態に合っていない状態です。
そのため次のフェーズでは、
- premium の分布を観測し
- その分布に合わせて threshold を調整する
という作業が必要になります。
Forward と Judgment の距離がまだ近すぎる
もう一つの問題は、Forward層とJudgment層の関係です。
現在のダッシュボードでは、
- Forward層の指標
- Judgment層の指標
が同じ画面に並んでいます。
これは便利ではあるのですが、実際に運用してみると、
Forward の値が強い ↓ Judgment スコアも強くなる
という形で、Forward層の値がそのまま Judgment層に影響してしまうケースが見えてきました。
たとえば、premium が常に大きい環境では、
- persistence
- reversion strength
といった指標が 常に高い値に張り付くことがあります。
これは「戦略が成立している」という意味ではなく、
Forward の指標が飽和している
だけの可能性があります。
この問題は、Judgment層の設計を見直す必要があることを示しています。
たとえば、
- 正規化方法
- スコア計算
- threshold
といった部分を、Forward層とは別の観点で設計する必要があります。
チューニングシステムの信頼度
最後に、チューニングシステムについてです。
現在の multi_market_probe には、メトリクスやログをもとにパラメータ調整の提案を行う 半自動チューニング機構があります。
ただし、実際に使ってみると分かったのは、
このレポートをそのまま信頼するのは危険
という点です。
理由は単純で、
- 一部の指標は proxy で再構成されている
- 観測サンプルがまだ十分ではない
- 市場分布がまだ理解できていない
からです。
そのため、現時点では
チューニング結果 = 参考情報
という扱いにしています。
自動適用を入れていないのも、この理由です。
観測器が動いたことで見えてきたこと
ここまでの問題をまとめると、現状は次のような段階にいます。
観測器の構造 → おおむね完成 市場分布 → まだ理解途中 戦略判断 → これから設計
つまり、今見えている問題の多くは
- 実装の問題ではなく
- 市場理解の問題
です。
これはむしろ、観測器としては正常な状態とも言えます。
観測装置が動き始めたことで、初めて「どこが分かっていないのか」が見えるようになったからです。
次の章では、この状況を踏まえて、今後どの部分を優先して詰めていくべきかを整理します。
8. チューニングシステムの現状
multi_market_probe には、現在 半自動のチューニングシステムを組み込んでいます。
これは、観測ログやメトリクスをもとに、設定パラメータの調整案を生成する仕組みです。
ただし、このチューニング機構は「自動最適化エンジン」ではありません。
現時点ではあくまで
設定変更の候補を提示する
という役割にとどめています。
つまり、
- パラメータの変更案は出す
- しかしそのまま自動適用はしない
という review-first の設計になっています。
なぜ自動適用にしていないのか
チューニングシステムを設計するとき、最初に迷ったのは
どこまで自動化するかという点でした。
理想だけを言えば、
観測ログ ↓ 最適パラメータ探索 ↓ 自動反映
という完全自動化が魅力的に見えます。
しかし実際には、この段階でそれをやるのはかなり危険です。
理由はいくつかあります。
まず、観測器自体がまだプロトタイプ段階であり、
Forward層やJudgment層の指標が 本当に市場を正しく表しているかが確定していません。
もしこの状態で自動チューニングを回してしまうと、
誤った指標 ↓ 誤った最適化 ↓ 誤った設定
というループが生まれる可能性があります。
そのため現在のチューニングシステムでは、
変更提案は出すが 最終判断は人間が行う
という設計にしています。
現在のチューニングの対象
現状のチューニングレポートでは、主に次のような項目を対象にしています。
- データ鮮度の閾値(stale 判定)
- premium の観測閾値
- 相関計算に必要なサンプル数
- premium persistence の条件
- 各市場の品質指標
これらはすべて、観測器が正しく動くための環境パラメータです。
ここでやっていることは、戦略の最適化というよりも
観測装置のキャリブレーション
に近い作業です。
たとえば、
- データ更新が遅い市場に対して stale 判定が厳しすぎる
- premium threshold が市場分布に対して低すぎる
- 相関計算のサンプル数が不足している
といった問題が見つかれば、それをレポートとして提示します。
ログからの統計再構成
現在のチューニングシステムでは、
メトリクスのスナップショットだけでなく、イベントログから統計を再構成するモードも用意しています。
このモードでは、たとえば次のような情報を再集計しています。
- feed quality の統計
- premium persistence の分布
- lead-lag スコアの履歴
- future outcome のサンプル数
これによって、短時間のメトリクスでは見えない
長時間の市場分布
を確認できるようになります。
ただし、この再構成には一部 proxy 指標も含まれているため、
レポートの数値を そのまま戦略判断に使うことは避けています。
現在の位置づけ
現時点でのチューニングシステムの役割をまとめると、次のようになります。
観測ログ ↓ 統計レポート ↓ 設定変更候補 ↓ 人間がレビュー
つまり、
- 戦略を自動生成する装置ではなく
- 観測器の状態を点検する装置
として使っています。
将来的な方向
将来的には、このチューニングシステムをもう少し発展させたいと考えています。
具体的には、
- パラメータ探索の自動化
- 分布に基づく threshold 調整
- 戦略別の最適パラメータ探索
といった方向です。
ただし、それを本格的に行うのは
Forward層の指標が安定し 市場分布がある程度理解できてから
になると思います。
現段階ではまだ、
観測器そのものを市場に合わせて調整するフェーズです。
そのためチューニングシステムも、
完全な自動化ではなく 補助ツールとして運用しています。
9. 次に詰めるべきポイント
ここまで見てきたように、multi_market_probe の観測器としての枠組みは一通り整いました。
Forward層で市場状態を観測し、Judgment層で戦略ごとの視点に整理し、ダッシュボードで可視化するという基本構造は、プロトタイプとしては十分に動いています。
ただし、ここから先の作業は「機能追加」ではありません。
むしろ重要になるのは、今ある指標が本当に意味を持っているのかを検証することです。
現在の段階で、特に優先して詰める必要があるポイントは大きく三つあります。
1. Forward指標の分布を正しく理解する
まず最初に行うべきなのは、Forward層の指標そのものの分布を理解することです。
具体的には、
- premium の分布
- persistence の継続時間
- future outcome の変化量
といった指標が、実際の市場でどのような形をしているのかを確認します。
たとえば、現在の観測では一部の市場ペアで
premium ≥ 10bps 発生率 ≈ 100%
という状態が見えています。
この場合、premium の存在そのものには情報量がありません。
重要になるのは、
平均からどれだけ外れているか
という観点です。
つまり、Forward層の指標を使う前に、
- どの値が通常状態なのか
- どの値が異常状態なのか
という 分布の基準を作る必要があります。
2. future outcome の時間軸を検証する
次に重要なのが、future outcome の **観測時間(horizon)**です。
現在のプロトタイプでは、主に 30秒後の premium 変化を記録しています。
これは短期挙動を確認するための暫定設定です。
しかし実際には、
- 数秒で収束する歪み
- 数十秒続く歪み
- 数分かけて解消される歪み
といった、複数の時間スケールが存在する可能性があります。
そのため、次のフェーズでは
30秒 60秒 180秒
といった複数の horizon を比較し、
どの時間幅で回帰傾向が最も強く現れるのか
を確認する必要があります。
これは Reversion 戦略を考えるうえで、非常に重要なポイントになります。
3. Judgment層のスコア設計を見直す
三つ目は、Judgment層の指標設計です。
現在のダッシュボードでは、
- Reversion strength
- Lead-Lag strength
- Hedge feasibility
といった形で戦略ごとの指標を整理しています。
ただし、実際に観測してみると、
- premium が常に大きい環境ではスコアが飽和する
- persistence が長いだけで回帰スコアが上がる
といった 設計上の偏りが見えてきました。
これは実装ミスではなく、むしろ
Forward層の値がそのままJudgment層に影響している
という構造的な問題です。
そのため次のフェーズでは、
- スコアの正規化方法
- threshold の設定
- Forward指標との依存関係
を見直し、Judgment層の設計をより独立したものにする必要があります。
4. premium の時間帯構造を調べる
もう一つ気になっているのが、premium の 時間帯変化です。
現在の観測では、一部の市場ペアで premium がほぼ常時存在しています。
しかしこの状態が、
- アジア時間
- 欧州時間
- 米国時間
で同じなのかどうかは、まだ確認できていません。
もし時間帯によって premium の平均水準が変わるなら、
市場構造そのものが時間帯依存
という可能性があります。
この場合、戦略設計も
- 時間帯別の threshold
- 時間帯別の回帰条件
といった形に分ける必要が出てきます。
5. 今のフェーズは「戦略を作る段階ではない」
ここまでのポイントをまとめると、現在のフェーズは
観測器を作る ↓ 分布を理解する ↓ 解釈を調整する
という段階です。
つまり、
戦略を決める段階ではない
ということです。
ここで焦って戦略ルールを作ってしまうと、
- 分布を誤解したまま
- 偶然のサンプルに引きずられて
戦略を設計してしまう可能性があります。
そのため、次の開発フェーズでは
- 新しい機能の追加
- 新しい戦略の実装
といったことは一旦後回しにし、
まずは Forward層の分布理解と Judgment層の設計調整に集中する予定です。
観測器としての精度が十分に上がった段階で、初めて
「どの戦略が成立するのか」を判断できるようになります。
10. 今日の結論
今回の開発で整理できたことを一言でまとめると、multi_market_probe は トレードボットではなく、戦略の存在を検出する観測器であるという点です。
Forward層では、市場間の状態をそのまま記録します。
premium、persistence、future outcome といった指標は、いずれも「市場で何が起きたか」を記述するためのものです。この段階ではまだ、戦略判断は行いません。あるのは 観測された事実とその分布だけです。
その上にある Judgment層では、それらの観測結果を
- Reversion(歪み回帰)
- Lead-Lag(リード/ラグ)
- Hedge(ヘッジ)
といった戦略の視点で整理します。ここで初めて「どう読むか」という解釈が入ります。ただし、この層の指標は市場の事実そのものではなく、あくまで Forward層のデータを基にした解釈モデルです。
今回ダッシュボードを実際に動かしてみたことで、いくつか重要なことも見えてきました。
- premium はイベントではなく、背景状態として存在している可能性がある
- threshold の設定が市場分布と合っていない可能性がある
- Forward層の値が強すぎると Judgment層のスコアが飽和する
- チューニングシステムの結果は、まだそのまま信頼できる段階ではない
つまり、観測器の枠組みは動いていますが、市場分布の理解と指標設計の調整はまだ途中という状態です。
このボットの役割は、最初から「勝てる戦略」を作ることではありません。
むしろその前段として、
市場にその構造が存在するのか
を確認することです。
歪み回帰が成立するのか。
市場間のリード/ラグが存在するのか。
ヘッジ可能な価格差があるのか。
それらは仮説ではなく、観測された分布から判断する必要があります。
multi_market_probe は、そのための装置です。
現時点では、bitFlyer FX と bitFlyer 現物を中心にした最小構成の観測器が動き始めた段階です。ここから先は、実際の市場ログを使いながら Forward層の分布を理解し、Judgment層の設計を調整していくフェーズになります。
戦略を作るのは、そのあとです。
まずは市場を観測する。
その分布を理解する。
そして、その結果として構造が見えてくるなら、そのとき初めて戦略として採用する。
今回の開発は、その 観測フェーズの土台が整ったところまで来た、というのが今日の結論です。