
こんにちは、ぼっちbotterよだかです。
今回は、multi_market_probe の LeadLag 判定機について、ORDER_INTENT の REJECTED を「ただ落ちた」で終わらせず、その理由まで分解して見えるようにした話です。最初は Grafana のパネルが止まって見えたところから始まったのですが、実際にはシステム全体が止まっていたわけではなく、signal や order intent のどこで流れが詰まっているのかを切り分ける必要がありました。そこで今回は、既存パネルの意味を整理し直したうえで、REJECTED reason の観測を追加し、「なぜ落ちたのか」を事実ベースで追えるようにしました。その結果、現時点での主因が edge 不足ではなく cooldown や quality 側にあることが見え、次に見るべき論点もかなり絞れてきました。
-

-
🛠️開発記録#496(2026/3/29)multi_market_probe開発ログ ― リードラグが事実ベースで“実行候補”に見え始めた話
続きを見る
1. 今日のゴール:執行へ進む前に、まず現状把握をやり切る
今回の作業で最初に置いたゴールは、LeadLag の判定機をそのまま執行部へつなぐことではありませんでした。むしろ逆で、「いま何が起きているのかを曖昧なまま次へ進めないこと」を優先しました。
前日の時点では、LeadLag 系の SIGNAL や ORDER_INTENT が動いているようにも見える一方で、Grafana 上のパネル表示にはフラットに見える箇所もありました。こういう状況は厄介です。システム全体が止まっているのか、観測は動いているが signal 段で落ちているのか、あるいは ORDER_INTENT の段で reject されているのかで、意味がまったく変わってくるからです。ここを曖昧にしたまま「シグナルが弱い」「もう少し閾値を緩めよう」と進んでしまうと、直す場所を間違えます。
特に今回扱っている LeadLag 判定機は、まだ研究用の観測機です。SIGNAL が出たからといって、そのまま「執行してよい」という意味にはなりませんし、ORDER_INTENT の ACCEPTED / REJECTED も、実際の約定結果ではなく、内部ゲートを通したかどうかの判定にすぎません。つまり、表示されている数字や線の意味を取り違えると、観測機を読んでいるつもりで、実際には別のものを見てしまう危険がありました。
そこで今回は、まず現状把握から入ることにしました。具体的には、Grafana の既存4パネルがそれぞれ何を表しているのかを整理し、観測機が止まっているのか、signal が止まっているのか、order intent が止まっているのかを切り分けること。そしてそのうえで、REJECTED が多いなら「どの理由で落ちているのか」まで掘って、次に見るべき論点を細くすることを目標に置きました。
要するに、今回のテーマは「LeadLag を今すぐ執行へつなぐこと」ではなく、「執行へ進めるだけの現状理解を作ること」でした。地味ですが、この順番を守ることが結果的には近道だと思っています。少なくとも私は、曖昧な理解のまま進んで後で手戻りするより、まず何が見えていて何がまだ見えていないのかを固めてから次へ進みたいタイプです。今回の作業は、その確認から始まりました。
2. パネル停止に見えたものの正体:止まっていたのはシステム全体ではなく gate だった
作業の最初に引っかかったのは、Grafana の一部パネルがフラットに見えていたことでした。こういうときにまず怖いのは、「観測機そのものが止まっているのではないか」という疑いです。実際、SIGNAL や ORDER_INTENT の rate 系パネルが動いていないように見えると、ついそう考えたくなります。
ただ、ここで雑に「止まっている」と判断してしまうと危ないので、まずは稼働状態を事実ベースで確認することにしました。ingest / metrics / persist / prometheus / grafana の各プロセスが生きているか、ログや signal stream が更新されているか、Prometheus API で実際にメトリクス値が返っているか、といった基本的なところから見直しました。
その結果、分かったのは、システム全体が落ちていたわけではないということです。観測機自体は動いていて、ログも更新されていました。つまり、少なくとも「ll-up 全停止」ではありませんでした。問題はそこではなく、signal 段の通過条件にありました。
当時の状態では、leadlag SIGNAL は出ていても、そのほとんどが signal_pass=false になっていました。そしてさらに掘ると、その主因は data_ok=false でした。ここで重要なのは、「シグナル候補が発生していない」のではなく、「候補はあるが data 側の条件で通らない」という構造だったことです。見た目にはパネルが止まっているようでも、実際には候補が gate で落とされ続けていた、というのが正体でした。
この切り分けはかなり大きかったです。もしシステム全体が止まっているなら、まずやるべきことはプロセスや配線の復旧になります。一方で、観測は動いていて signal だけが落ちているなら、見るべきなのは判定条件や feed 品質のほうです。今回は後者でした。
さらに確認を進めると、当時は bf_fx と binance_perp が LIVE を維持できておらず、DEGRADED や CONNECTING に落ちる時間帯がありました。LeadLag の signal 判定では allow_degraded=false の条件が効いていたため、どちらかが LIVE でないだけで data_ok=false になります。つまり、パネルが静かに見えた背景には、「候補がない」のではなく、「feed 品質条件により signal 段でブロックされていた」という事情がありました。
ここでようやく、問題の場所がかなり細くなりました。壊れていたのは観測機全体ではなく、より正確に言えば「観測機が返している feed 状態と、それを gate している signal 条件の関係」でした。私は今回、この切り分けができた時点で、作業の半分くらいは終わった感覚がありました。どこで詰まっているのかが分かれば、少なくとも闇雲に触らずに済むからです。
今回のパネル停止に見えたものの正体は、システム停止ではありませんでした。候補は出ていたが、data 側の gate を通れず、結果として下流のパネルが静かに見えていた。まずこの事実を押さえられたことで、次にやるべきことも自然に定まりました。
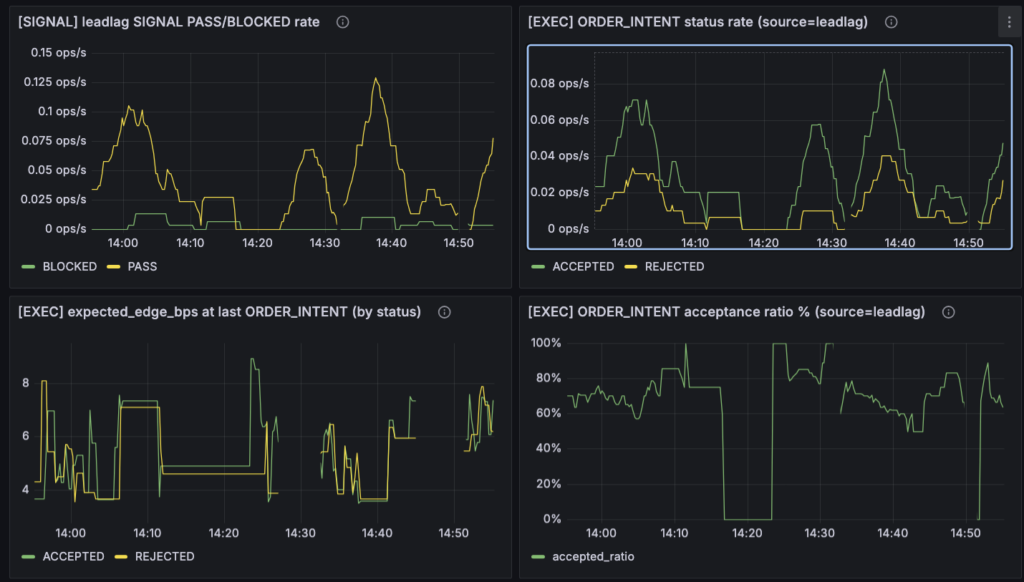
3. 4枚のパネルを読み直す:SIGNAL と ORDER_INTENT は何を表しているのか
システム全体は止まっていない、ただ signal 段で gate に引っかかっていた。そこまでは切り分けられたのですが、それだけではまだ不十分でした。次に必要だったのは、Grafana 上で見ている4枚のパネルが、それぞれ何を表しているのかをきちんと整理することです。
今回ここを改めて見直した理由は単純で、パネルの意味を取り違えると、観測機の現在地を誤読するからです。たとえば SIGNAL の PASS/BLOCKED rate と ORDER_INTENT の ACCEPTED/REJECTED rate は、どちらも「通った」「落ちた」を表しているように見えますが、実際には見ている段階が違います。この違いが曖昧なままだと、signal 判定の話をしているつもりで order intent の話をしていたり、その逆が起きたりします。
まず、[SIGNAL] leadlag SIGNAL PASS/BLOCKED rate は、leadlag シグナルが signal stream に出る段階で、通過したかブロックされたかの頻度を見ています。ここでの PASS/BLOCKED は、構造判定やデータ条件などを含んだ「signal 段の通過可否」です。つまり、この段階ではまだ「執行候補」ではなく、あくまで leadlag シグナルとして出せるかどうかを見ています。
一方で、[EXEC] ORDER_INTENT status rate (source=leadlag) は、その signal を受けて作られた ORDER_INTENT が、最終的に ACCEPTED になったか REJECTED になったかを見ています。ここで重要なのは、ORDER_INTENT は実際の約定結果ではないということです。取引所に注文が通ったか、儲かったか、という話ではありません。内部ロジック上で「執行候補として通すかどうか」を判断した結果にすぎません。この ACCEPTED / REJECTED を、売買の成否や収益の良し悪しと同一視すると、途端に話がずれてしまいます。
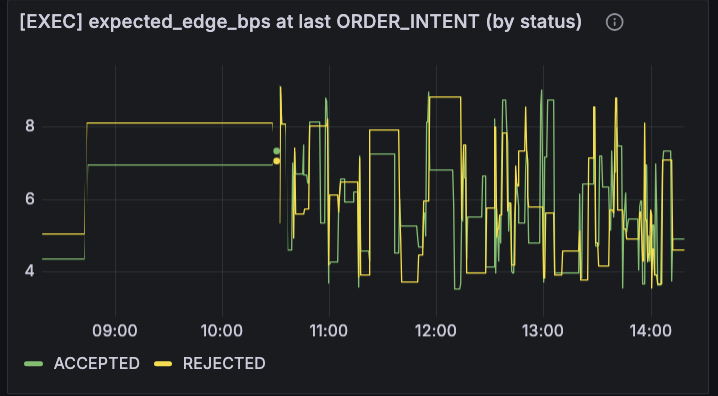
さらに、[EXEC] expected_edge_bps at last ORDER_INTENT (by status) も誤読しやすいパネルでした。これは平均値ではなく、直近の ORDER_INTENT 発生時点における expected_edge_bps の最新値です。しかもこの expected_edge_bps は runtime 上の推定値であって、研究用の EV や実現損益と同じ尺度ではありません。したがって、このパネルを見て「ACCEPTED は常に高エッジ、REJECTED は常に低エッジ」と単純に読めるわけではありません。実際、REJECTED 側に高い値が出ていることもありました。
最後の [EXEC] ORDER_INTENT acceptance ratio % (source=leadlag) も、最初は少し誤解しやすいものでした。ぱっと見だと「今の LeadLag 構造がどれだけ有効か」のように読みたくなりますが、実際に表しているのは、現行の gate 設定のもとで ORDER_INTENT がどれだけ ACCEPTED になっているかという通過率です。つまり、収益性そのものではなく、執行候補として内部的に通している割合を示しているにすぎません。
こうして整理してみると、この4枚はそれぞれ役割が違います。SIGNAL のパネルは signal 段での候補通過、ORDER_INTENT のパネルは執行候補段での採否、expected_edge はその時点の runtime 推定、acceptance ratio はその通過率です。全部をまとめて「シグナルが良いか悪いか」と読もうとすると、情報が混ざってしまいます。
今回ここを読み直したことで、少なくとも「どの段階で何が起きているのか」はかなり明確になりました。上流の signal 段で止まっているのか、下流の order intent 段で落ちているのか、それとも edge 推定や gate 設計の問題なのか。今後の修正を考えるうえでも、この分離は避けて通れない整理だったと思います。
4. REJECTED が多い、では足りない:理由を観測する必要があった
4枚のパネルを読み直してみると、少なくとも「どの段階で止まっているか」はかなり分かるようになりました。SIGNAL 段で落ちているのか、ORDER_INTENT 段で落ちているのか、その切り分け自体はもうできます。ただ、そこで次にぶつかったのが、「REJECTED が出ていること自体は分かるが、なぜ落ちたのかがまだ分からない」という問題でした。
これは地味ですが、かなり大きい問題です。たとえば ORDER_INTENT の REJECTED が多いとしても、その主因が EDGE_TOO_LOW なのか、COOLDOWN_ACTIVE なのか、あるいは LIVE_DATA_REQUIRED や QUALITY_NG なのかで、意味はまったく変わってきます。もし edge 不足が主因なら、構造そのものが弱いか、runtime の期待値見積もりが厳しすぎる可能性を疑うべきです。一方で cooldown が主因なら、構造候補は来ているが、頻度制御の都合で止めていることになります。quality 側なら、構造より前に feed や品質条件の問題を見直すべきかもしれません。つまり、同じ REJECTED でも、原因が違えば次に触るべき場所もまるで違うわけです。
ここで改めて感じたのは、これまで見ていた ORDER_INTENT status rate だけでは、まだ情報が粗いということでした。ACCEPTED と REJECTED の件数や比率を見ること自体は無駄ではありません。ただ、それだけでは「厳しく選別できている」のか「必要以上に止めている」のかが分からない。特に今回のように、REJECTED 側の expected_edge_bps がそこまで低く見えない場面があると、なおさらです。実際、ダッシュボードの既存パネルでは expected_edge_bps を status 別には見えても、REJECTED の中身までは分解できない構成でした。
そこで今回、必要だと思ったのが「REJECTED を理由ごとに観測すること」でした。ORDER_INTENT はすでに内部ゲート通過判定として扱っているので、その最終結果に reason_code を持たせれば、なぜ落ちたのかを後から集計できるようになります。この方向はコード上でも自然で、すでに PASSED_GATE、EDGE_TOO_LOW、COOLDOWN_ACTIVE、LIVE_DATA_REQUIRED、HEDGE_UNAVAILABLE、SIGNAL_BLOCKED、QUALITY_NG、UNKNOWN_FALLBACK といった固定列挙の reason が定義できる形になっていました。free text ではなく固定列挙にしておけば、Prometheus に流したあとも reason 別に素直に集計できます。
現段階で大事なのは、reject を減らすことではありません。まず必要なのは、「何が理由で落ちているのか」を見えるようにすることでした。ここを飛ばして cooldown を緩めたり、quality 条件を外したりすると、改善のつもりで単に gate を壊すだけになりかねません。私が今回やりたかったのは、REJECTED の“量”をいじることではなく、REJECTED の“意味”を読めるようにすることでした。
そのために、ダッシュボード側でも REJECTED reason rate、REJECTED reason share %、expected_edge_bps by reason_code を追加する方針にしました。これがあれば、「今の REJECTED の主因は何か」「その理由はどれくらいの比率を占めているか」「高い edge を持っているのに別理由で落ちている個体があるか」を一段細かく見られます。実際、ダッシュボード定義もその意図で作っていて、obx_mmarb_order_intent_rejected_total と reason ごとの expected edge を表示する構成になっています。
要するに、REJECTED が多いという事実だけでは、まだ何も決められないということです。必要なのは、その REJECTED が「正しく危険を弾いている reject」なのか、「本来通すべき候補まで落としている reject」なのかを分けることでした。今回の作業は、その切り分けをするための観測軸を、ようやく足した段階だったと思っています。
5. 今回の実装:reason_code を追加し、REJECTED を分解した
ここまでで、「REJECTED が出ている」こと自体は観測できるようになっていました。ただ、それだけではまだ粗い。そこで今回やったのは、ORDER_INTENT に reason_code を持たせて、REJECTED を“理由ごとに読める”ようにすることでした。
実装の考え方はシンプルです。ORDER_INTENT の最終 status が ACCEPTED か REJECTED かだけを持っていても、あとから見返したときに分かるのは「落ちた」という事実だけです。これでは、構造が弱いから落ちたのか、品質条件で止めたのか、cooldown で連打抑制されたのかが分かりません。そこで、最終判定の主因を reason_code として明示的に残すようにしました。コード上でも PASSED_GATE、EDGE_TOO_LOW、COOLDOWN_ACTIVE、LIVE_DATA_REQUIRED、HEDGE_UNAVAILABLE、SIGNAL_BLOCKED、QUALITY_NG、UNKNOWN_FALLBACK が定義されており、意図どおり固定列挙で扱える形になっています。
この fixed enum にしたのはかなり重要でした。もしここを文字列の自由記述にしてしまうと、Prometheus に流したあとに集計が崩れます。同じ意味でも表記ゆれが起きますし、Grafana 側で reason ごとの比較がしづらくなります。今回は最初から「後で集計する」前提で、観測に向いた形に寄せました。
さらに、メトリクス側にもこの軸を通しました。obx_mmarb_order_intent_total は status に加えて reason_code を持つようになっており、REJECTED 専用には obx_mmarb_order_intent_rejected_total も用意されています。加えて、reason ごとの expected_edge_bps を見るための系列も生えているので、「どの理由で落ちたか」だけでなく、「どれくらいの expected edge を持っていた個体がその理由で落ちたか」まで追える構成になっています。メトリクス定義を見る限り、今回必要だった観測軸はひと通り揃いました。
ダッシュボード側も、その意図に合わせて増やしました。今回追加したのは、[EXEC] ORDER_INTENT REJECTED reason rate、[EXEC] ORDER_INTENT REJECTED reason share %、[EXEC] expected_edge_bps by reason_code の3枚です。1枚目は reject の主因を 5分 rate で見るため、2枚目は rejected 全体に占める reason ごとの比率を見るため、3枚目は「高い expected edge を持っているのに別理由で落ちていないか」を補助的に確認するためのものです。ダッシュボードJSON上でも、この3枚はまさにその目的で設計されています。
今回この3枚を足したことで、ようやく既存4パネルと新しい reason 軸がつながりました。これまでは
- SIGNAL がどれだけ通っているか
- ORDER_INTENT がどれだけ ACCEPTED / REJECTED か
- 直近の expected_edge はどれくらいか
- acceptance ratio はどれくらいか
までは見えていましたが、REJECTED の中身は空白でした。そこに今回、
- 何理由で落ちたのか
- その理由はどれくらいの比率か
- その理由で落ちた個体の edge はどれくらいか
が加わったことで、観測機としての解像度が一段上がりました。
もちろん、実装は途中で少し詰まりました。特に REJECTED reason share % パネルは最初 No data になっていて、reason ごとのカウント自体は出ているのに share 表示が繋がっていない状態でした。ただ、そこも修正できたことで、最終的には reason rate と share の両方が読めるようになりました。ここが通ったことで、「reason_code は実装したが、使い物になるかはまだ不明」という段階から、一応「観測に使える状態」までは持っていけたと思っています。
今回の実装でやりたかったのは、ロジックを賢くすることではありませんでした。やったのはむしろ逆で、いま起きている reject を、後から人間が読める形にすることです。私は今回、この観測軸を追加したことで、ようやく「なぜ落ちたのか」を事実ベースで議論できる入り口に立てた気がしています。
6. 実際に見えたこと:主因は edge 不足ではなく cooldown / quality だった
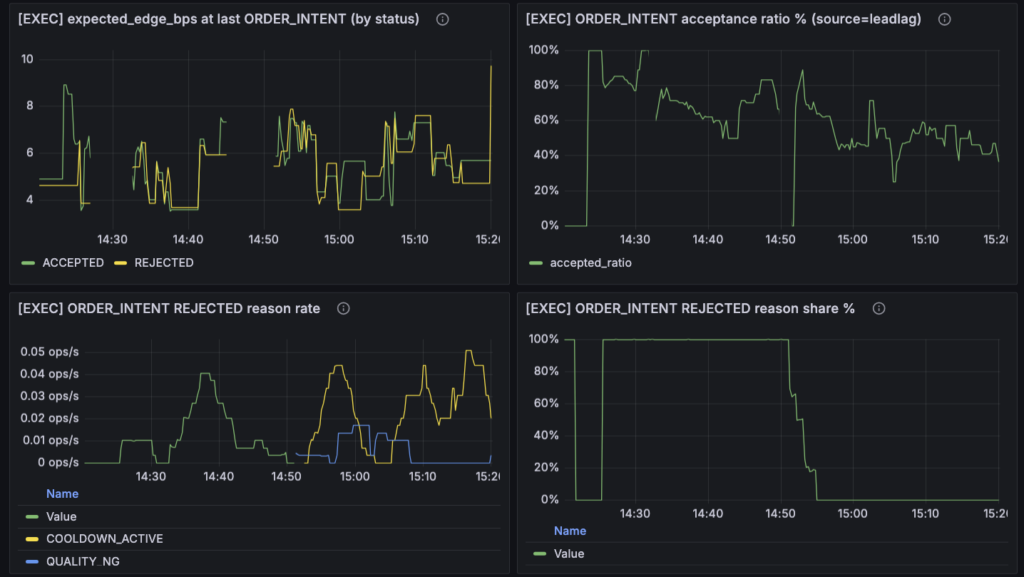
reason_code を追加してパネルまで通したことで、ようやく REJECTED の中身を見られるようになりました。今回ここで一番大きかったのは、「REJECTED が出ている」という事実そのものよりも、その主因が何かが見えたことです。
結論から言うと、現時点での主因は EDGE_TOO_LOW ではありませんでした。実際に見えてきたのは、COOLDOWN_ACTIVE が主で、QUALITY_NG がそれに続く形です。少なくとも今回観測した時間帯では、「構造候補が弱すぎて通らない」というより、「候補はあるが運用ゲート側で止めている」状態として読むほうが自然でした。追加した reason パネル自体も、その切り分けをするために入れたものです。
これはかなり重要です。もし EDGE_TOO_LOW が REJECTED の中心なら、まず疑うべきは構造そのものです。LeadLag の定義が弱いのか、runtime の期待値見積もりが厳しすぎるのか、あるいは research 側で見えていたものが execution 候補としては細すぎるのか、といった話になります。けれども、今回見えてきた主因はそこではなかった。つまり、少なくとも今の段階では「構造が死んでいる」と決めつけるには早い、ということです。
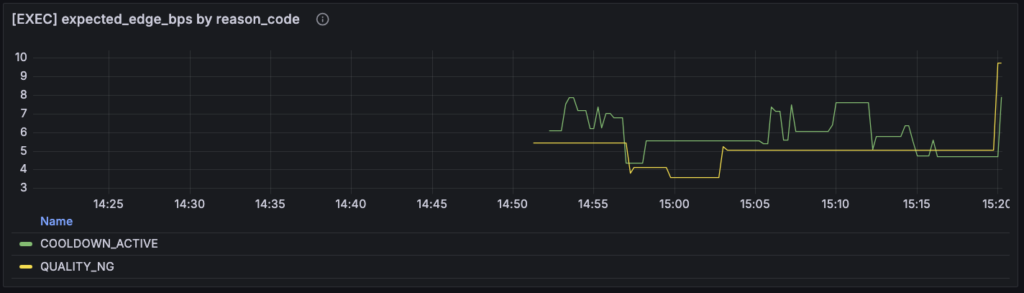
さらに補助的に効いたのが、expected_edge_bps by reason_code のパネルでした。ここでも、COOLDOWN_ACTIVE 側に 6〜8bps 台の個体が見えていました。つまり、「それなりの expected edge を持っていそうな候補でも、cooldown で落ちているものがある」ということです。これは逆に言えば、REJECTED という結果だけを見ていた頃には分からなかった情報でした。以前は、REJECTED 側の edge が高く見えても「何が起きているのか」が曖昧でしたが、いまは少なくとも一部は cooldown 理由で説明できます。ダッシュボード上でも、このパネルはまさにその補助観測として置かれています。
一方で、QUALITY_NG も無視できるほど小さくはありませんでした。ここでいう quality は、単純な feed の生死だけではなく、signal engine 側の quality flag 群をまとめたラベルです。コード上でも quality に関わる flag は一まとまりに扱われていて、少なくとも今は「品質側で落ちた」という一段の分類までは見えるようになっています。まだその中身が spread なのか、liq なのか、stability なのか、score なのかまでは割れていませんが、少なくとも「edge 不足ではなく quality 側で落ちている rejected がある」という認識はかなり大きいです。
ここで大事なのは、今回見えたものを過大評価しないことでもあります。今回の観測で言えるのは、「今の rejected 主因は cooldown / quality に寄っている時間帯がある」ということです。逆に言えば、まだ COOLDOWN_ACTIVE が本当に良い抑制なのか、単なる取り逃しなのかまでは分かっていません。QUALITY_NG にしても、それが妥当な防御なのか、無駄に gate が厳しいだけなのかはまだ未確定です。見えるようにはなったけれど、評価はこれからという段階です。
ただ、それでも今回の進捗は大きいと思っています。以前は「REJECTED が多い」という粗い認識しか持てなかったものが、いまは少なくとも
- edge 不足で落ちているのか
- cooldown で落ちているのか
- quality で落ちているのか
を分けて見られるようになったからです。これは、そのまま次にどこを掘るべきかを決める材料になります。今回の時点で言えるのは、LeadLag の白黒を出すために、まず見るべき論点が「構造そのもの」から「運用ゲートの妥当性」へ少し寄ってきた、ということでした。
7. 現時点の結論:LeadLagは保留継続、ただし執行GOにはまだ早い
ここまで整理してきた内容を踏まえると、現時点での結論はかなりはっきりしています。
LeadLag は、少なくとも今すぐ捨てる対象ではありません。ただし、そのまま「執行につないでよい」と言える段階でもありません。言い方をまとめるなら、エッジ候補としては保留継続、執行直結としてはまだ未完成という位置づけです。
今回そう判断した理由は、まず SIGNAL も ORDER_INTENT も完全には止まっておらず、accepted まで含めて継続的に出ているからです。つまり、候補生成そのものが死んでいるわけではありません。もし構造がまったく機能していないなら、もっと上流の段階から沈黙に近いはずですが、現状はそうではありません。ダッシュボード上でも、既存の signal / order intent 系パネルは再び動いており、LeadLag 系の流れ自体は生きています。
次に、今回 reason を分解して見えた rejected 主因が EDGE_TOO_LOW ではなく、主に COOLDOWN_ACTIVE と QUALITY_NG に寄っていたことも大きいです。これは、「構造候補が弱すぎて通らない」というより、「候補はあるが運用ゲート側で止めている」状態に近いことを意味します。ここを見ずに「accepted が少ないから構造が弱い」と言ってしまうのは、かなり危ない読み方でした。少なくとも今の段階では、LeadLag の構造そのものに即座に撤退判定を出すには材料が足りません。
ただし同時に、執行GOに進めるにはまだ早いです。理由はシンプルで、今見えている expected_edge_bps は runtime の推定値であって、研究EVや実現損益そのものではないからです。ダッシュボードの説明にも、これは signal_strength - expected_slip - expected_fee による runtime estimate であり、研究EVとは別尺度だと明記されています。サービス側でも、research の roundtrip cost と runtime expected edge は意図的に分離されており、この分離はまだ崩してはいけない段階です。
つまり、いま分かったのは「何が gate されているか」であって、「その gate を外したら儲かるか」ではありません。ここを飛ばして自動執行へ進むと、せっかく観測機を整えた意味が薄れます。今回の進捗でようやく見えるようになったのは、どこを掘れば白黒を出せるかという入口です。まだ白黒そのものが確定したわけではありません。
だから、今回の結論は少し地味ですが、私はかなり納得しています。
LeadLag は、研究テーマとしてはまだ候補圏内にあります。reject の主因が edge 不足に寄り切っていない以上、ここで切るのは少し早い。一方で、執行系としてはまだ「候補生成と gate 観測」の段階にいて、paper や shadow を含めた事後整合なしに GO を出せる状態ではない。この距離感は、たぶん今の自分にとってちょうどいいと思っています。
要するに、現時点での立ち位置はこうです。
LeadLag はまだ残す。ただし、期待して飛びつくのではなく、もう一段だけ事実を積んでから白黒を出す。
今回ここまで来て、ようやくそう言える状態になりました。
8. 次に検証すること:cooldown は良い抑制か、取り逃しか
今回の作業で、LeadLag の REJECTED を理由ごとに見えるようにしたことで、ようやく次に検証するべき論点もかなり絞れました。現時点で一番大きいのは、やはり COOLDOWN_ACTIVE をどう評価するかです。今回見えた rejected の主因は edge 不足ではなく cooldown 側に寄っていました。ということは、今後の白黒を出すうえで重要なのは、「cooldown が危険な連打を正しく抑えているのか」、それとも「本来通すべき候補まで落としているのか」を見極めることになります。
ここは、数字だけ見て緩めればよいという話ではありません。もし cooldown が良い抑制として機能しているなら、安易に外すとノイズの多い signal を増やし、結果的に判定機全体を弱くしてしまう可能性があります。逆に、一定以上の expected edge を持った候補が繰り返し cooldown だけで落ちているなら、今の設計は少し厳しすぎるかもしれません。だから次にやるべきことは、cooldown に引っかかった個体をもう少し丁寧に見て、accepted 側との違いを確かめることだと思っています。
もう一つの論点は QUALITY_NG の中身です。今回の reason 分解で、quality 側でも rejected が出ていることは分かりました。ただ、現時点ではそれが「品質NG」という一段のラベルでしか見えていません。実際には、その中に spread 条件なのか、liq 条件なのか、stability や score なのか、といった異なる理由が混ざっているはずです。もしここが次のボトルネックになるなら、quality をさらに一段分解して見ないと、やはり改善先を間違えます。
そして最終的には、accepted / rejected と paper あるいは shadow の結果を突き合わせる必要があります。今回見えている expected_edge_bps は runtime の推定値であって、実際の損益そのものではありません。だから、「cooldown で落ちたものを通したら本当に良かったのか」「quality で落としたものは本当に落として正解だったのか」は、結局のところ事後の結果と照らし合わせないと判断できません。今回の観測で、ようやくその比較をするための材料が揃ってきた、というのが正確なところです。
逆に、まだ触らないと決めていることもあります。ひとつは、REJECTED を減らすためにすぐ cooldown や quality 条件を緩めることです。いまはようやく「何理由で落ちているか」が見えた段階なので、ここで先に gate を緩めると、観測していたはずのものを自分で崩してしまう危険があります。もうひとつは、LeadLag の構造そのものをすぐ作り直すことです。少なくとも今の rejected 主因は edge 不足ではなく運用ゲート側に寄っているので、まずは gate の妥当性を見たほうが順番として自然です。
今回ここまで進めてみて、次の一歩はかなり明確になりました。
LeadLag の白黒を出すために、次に見るべきなのは「もっと強い signal を作ること」ではなく、「いま止めている signal の中に、止めるべきものと止めすぎているものがどれだけ混ざっているか」を確かめることです。私はたぶん、ここを見ないまま次へ進むと、また同じように数字だけを見て迷うと思います。だから次回は、この cooldown と quality の妥当性に、もう一段だけ踏み込んでみるつもりです。