
multi_market_probe_v1 の開発を進める中で、ある問題に直面しました。
メトリクスは揃っている。
WS化も完了し、一次情報の整合性も確認済み。
ダッシュボードは充実していて、状態はすべて緑。
それでも、戦略は前に進んでいませんでした。
原因は単純でした。
観測はできているが、解釈できていなかった。
他市場観測の目的は、主戦場(bf_fx)における歪みや乖離を定義し、トレードシグナルに接続することです。しかし、メトリクスが増えすぎたことで、何を優先して見るべきかが曖昧になっていました。
そこで一度、機能追加ではなく削減を選びました。
本記事では、multi_market_probe_v1 を「読める観測機」に戻すまでの再設計ログをまとめます。
Ⅰ. なぜメトリクスを削る必要があったのか
multi_market_probe_v1 は、開発を進めるたびにメトリクスが増えていきました。
- Feed State
- Live Flags
- Drop Rate
- Out-of-order Rate
- Latency p95
- Tick Gap
- Stale Book
- Spread Anomaly
- Premium Regime
- Edge / Cost / EV / Distortion / Signal Ready
設計としては正しい方向です。
観測可能なものはすべて観測し、異常を検知できるようにする。これは健全な開発の流れです。
しかし、ある時点で違和感が出てきました。
「全部緑なのに、不安が消えない。」
ダッシュボードは整っている。
データは流れている。
Health も LIVE を維持している。
それでも、
- どの指標を最優先で見るべきなのか
- どの状態が「解釈可能」なのか
- どこから先が戦略の入力として有効なのか
が曖昧になっていました。
問題は、メトリクスが多いことではありません。
問題は、読む順序と役割が定義されていないことでした。
観測機の目的は「正しさの証明」ではありません。
主戦場である bf_fx において、他市場との歪みを定義するための基盤を作ることです。
ところが、メトリクスが増えすぎた結果、
- Quality と Signal が同列に並び
- Health と Confidence が混在し
- 白黒判定と連続値評価が曖昧になっていました。
この状態では、いくら指標を増やしても戦略は前に進みません。
そこで一度立ち止まりました。
追加するのではなく、削る。
複雑にするのではなく、役割を整理する。
「観測できる」状態から、
「観測を解釈できる」状態へ戻すために、
メトリクスの削減を決断しました。
それが、今回の再設計の出発点です。
Ⅱ. ゴールの再定義:観測可能 ≠ 解釈可能
multi_market_probe_v1 を作り込んでいく中で、ひとつの前提に気づきました。
観測できていることと、解釈できていることは、まったく別物だということです。
WebSocket 化を進め、一次情報の整合性を確認し、Health 判定も整理しました。
メトリクスは正しく出力され、Prometheus にも流れ、ダッシュボード上でも可視化できています。
つまり、「観測可能」な状態は達成できていました。
しかし、それがそのまま「戦略に使える状態」を意味するわけではありません。
たとえば、
- すべての市場が LIVE であること
- drop_rate や latency が閾値内に収まっていること
- confidence が 0.8 以上で推移していること
これらは重要な事実ですが、それだけでは「歪みをどう解釈するか」には直結しません。
観測可能とは、「値が取得できる」状態です。
解釈可能とは、「その値の意味が定義されている」状態です。
この違いを曖昧にしたままメトリクスを積み上げると、次のような状態になります。
- 指標は多いが、どれが前提条件なのか分からない
- 異常が出ても、それが戦略にどう影響するのか説明できない
- “全部緑”でも、何を信用してよいのか判断できない
これは設計上の問題です。
本来、multi_market_probe_v1 のゴールは明確でした。
他市場観測を通じて、主戦場(bf_fx)の歪みや乖離を定義し、
トレードシグナルへ接続すること。
であれば、必要なのは「できるだけ多く観測すること」ではなく、
- どのメトリクスが前提条件なのか
- どの状態から先が“解釈可能”なのか
- どの値がシグナル生成に直接関わるのか
を明確にすることです。
そこでゴールを再定義しました。
観測機の目的は、
“あらゆる異常を検知すること” ではなく、
歪みを定義できる状態を安定して作ること。
観測可能な状態から、
解釈可能な状態へ。
この再定義を起点に、ダッシュボードの構造とメトリクスの役割を整理していきました。
Ⅲ. ダッシュボード読解順の固定(Q→E→M→S)
メトリクスを削ると同時に、もうひとつ決めたことがあります。
ダッシュボードの読む順序を固定すること。
multi_market_probe_v1 は、構造として
[Q] → [E] → [M] → [S]
の順に読む設計にしました。
これは見た目の整理ではなく、解釈の前提条件を固定するためのルールです。
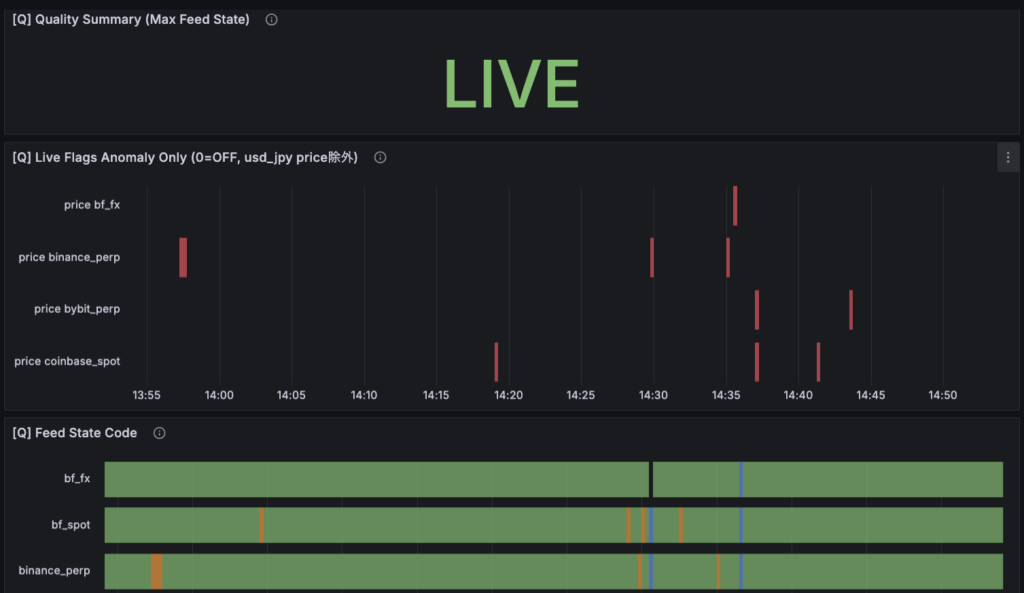
[Q] Quality — 観測は成立しているか
最初に確認するのは [Q] です。
- Feed State Code は LIVE か
- ingestion_live / price_live は維持されているか
- stale / tick_gap は許容範囲か
- latency は異常値を出していないか
ここが崩れている場合、後段の解釈は無効です。
どれだけ edge_net が大きくても、
どれだけ signal_strength が強くても、
観測自体が崩れているなら、それはノイズです。
まず「観測が成立している」ことを確認する。
これが最初の前提です。
[E] Error — どこで詰まっているか
次に見るのが [E] です。
- Pipeline Errors(10分増分)
- Stage Delay Max
ここでは、fetch / parse / compute / publish のどの段で遅延やエラーが発生しているかを確認します。
重要なのは、「異常があるか」だけでなく、「どの層で異常があるか」を特定できることです。
観測が崩れている場合、
- ネットワークか
- パースロジックか
- 計算負荷か
- 出力側か
を切り分けられる設計でなければ、デバッグは遅くなります。
[E] は、戦略のためではなく、
観測基盤を守るためのパネルです。
[M] Market — 状態はどうなっているか
[Q] と [E] が問題ないことを確認してから、ようやく [M] を見ます。
ここでは、
- Edge / Cost / edge_net
- EV / Distortion / Signal Ready
- Premium Regime
- FX依存度
といった、市場状態そのものを解釈します。
ここが初めて、「歪み」という概念が意味を持ちます。
観測が成立しているという前提の上で、
- これは国内主導か
- グローバル主導か
- 反転局面か
- 差引余地は正か
を読むことができます。
順序を守らないと、
観測異常を市場構造の変化と誤認するリスクが出ます。
[S] Signal — 採用するかどうか
最後に見るのが [S] です。
- Signal Code(方向)
- Signal Strength(強さ)
- Signal Confidence(鮮度由来の信頼度)
ここは「出ているかどうか」ではなく、
「採用するかどうか」を判断する領域です。
特に重要なのは Signal Confidence です。
方向が出ていても、confidence が低ければ採用しない。
ここで初めて、白黒の判断に落とし込みます。
読む順序を固定した意味
この Q→E→M→S の順序を固定したことで、
- どこから先が前提条件か
- どこから先が解釈領域か
- どこが最終判断か
が明確になりました。
結果として、「全部緑だけど不安」という状態が減りました。
ダッシュボードは、情報を並べるためのものではありません。
解釈の順序を固定するための装置です。
この順序を固定したことが、今回の再設計の大きな一歩でした。
Ⅳ. HealthとConfidenceを分離する設計
今回の再設計で、最も重要だったのはこの分離でした。
Health(生存判定)と
Confidence(信頼度評価)を混ぜないこと。
リアルタイム観測では、すべてを「良い/悪い」の二値で扱いたくなります。
しかし、それをやると設計はすぐに破綻します。
Health は白黒であるべき
Health が扱うのは、「壊れているかどうか」です。
- 受信が止まっていないか(DOWN判定)
- tick_gap が閾値を超えていないか
- パイプラインが詰まっていないか
- 重大なエラーが発生していないか
これらは連続値ではなく、構造の健全性の問題です。
壊れているかどうかにグラデーションを持たせると、
- なんとなく動いているからOK
- 少し遅いけどまあ大丈夫
といった曖昧な判断が入り込みます。
観測基盤は、壊れているなら壊れているとはっきり言うべきです。
だから Health は白黒です。
Confidence はグラデーションで扱う
一方で、すべてを白黒で扱うとノイズに振り回されます。
- 価格更新が少し遅れただけで無効
- 片側市場がわずかに古いだけで不採用
- latency が瞬間的に上振れしただけで停止
これでは実運用に耐えません。
そこで導入したのが Signal Confidence です。
freshness = 1 - max(base_stale, ref_stale) / stale_after
confidence = clip(freshness, 0, 1)
これは、
- どの程度古い情報を見ているのか
- どの程度その歪みを信用できるのか
を連続値で扱う設計です。
壊れていないが、少し古い。
問題はないが、完全ではない。
その曖昧さを数値で表現します。
“未知”をどう扱うか
WS世界では、すべての市場で遅延が測れるわけではありません。
たとえば、
- exchange_ts が取得できない市場
- recv_lag が計測不能な市場
これを 0 として扱うのは危険です。
そこで、
- latency_observable_flag
- latency_unknown_confidence_cap
を導入しました。
遅延が測れない市場は、
壊れているわけではないが、過信もしない。
という立ち位置に置きます。
これも白黒ではなく、グラデーションで扱う部分です。
なぜ分離が必要だったのか
Health と Confidence を混ぜてしまうと、
- 少し古いだけで DOWN 扱い
- DOWN していないから安心
- confidence が低いのに採用
といった設計矛盾が起きます。
今回、Health を「構造の健全性」、
Confidence を「情報の信頼度」と定義し直したことで、
- ダッシュボードの意味が明確になり
- シグナル採用の基準が整理され
- “全部緑”の解釈が安定しました。
設計思想としての整理
今回の再設計で固定したのは、次の原則です。
- 壊れているかどうかは白黒で扱う
- 信頼できるかどうかは連続値で扱う
- 未知は良好扱いしない
- 未知を即停止にも落とさない
この分離ができたことで、
観測機は「監視ツール」から「戦略の基盤」へと一段進みました。
Ⅴ. signal_confidence の実装と数式
ここからは、今回の再設計で一番「意味が固定できた」部分を書きます。
それが signal_confidence です。
multi_market_probe_v1 における signal_confidence は、ざっくり言えば
「この瞬間に参照している base/ref の情報は、どれくらい“新鮮”か」
を 0〜1 の連続値に正規化したものです。
1) 基本設計:freshness を 0〜1 に正規化する
定義はこの式です。
freshness = 1.0 - (max(base_stale_ms, ref_stale_ms) / stale_after_ms)
signal_confidence = clip(freshness, 0.0, 1.0)
base_stale_ms:base_market の「最後に新鮮と見なせる更新からの経過」ref_stale_ms:ref_market 側も同様stale_after_ms:その市場の“許容鮮度”を決めるスケール(市場別に設定)max(base_stale_ms, ref_stale_ms):片方でも古ければ保守的に落とす(=最も重要な思想)
この定義にした理由は明快で、
- マルチ市場観測では「片方だけ古い」が普通に起きる
- その状態で歪み・乖離を解釈すると、誤認が増える
からです。
つまり、弱いリンク(古い方)に合わせて信頼度を落とす設計です。
2) クリップ(clip)は “仕様としてのガード”
freshness は計算上、負にも 1超にもなり得ます。
- stale が stale_after を超えると freshness < 0
- stale が 0 に近いと freshness > 1 になり得る(実装や丸め次第)
そこで
signal_confidence = clip(freshness, 0.0, 1.0)
として、出力の意味を壊さないようにしています。
ここはテクニックというより、仕様を固定するための一手です。
3) “遅延が測れない市場” は過信しない(cap)
WS 化していくと、避けられない問題が出ます。
市場によっては exchange_ts(またはseq)が取れず、recv_lag_ms が測れない
たとえば Binance の bookTicker はケースによって exchange_ts が欠落します。
この場合、遅延が “良好” なのか “測れないだけ” なのかが区別できません。
そこで入れたのが latency_observable_flag と latency_unknown cap です。
設計はこうです。
if latency_observable_flag == 0:
signal_confidence = min(signal_confidence, latency_unknown_confidence_cap)
つまり、
- 遅延が測れる市場は freshness のまま評価する
- 遅延が測れない市場は confidence を上限で抑える(過信しない)
この cap は「未知=悪」ではなく、
「未知=過信しない」
という立ち位置を作るためのものです。
実務的には、これがあるだけで
- “全部緑”でも不安
- どこを信用していいか分からない
という状態から抜けやすくなります。
4) stale_after_ms は市場別に持つ(これが調整ノブ)
この confidence 設計の良いところは、チューニングが stale_after_ms に集約されることです。
stale_after_msを短くすると:鮮度に厳しくなり、confidence は落ちやすいstale_after_msを長くすると:鮮度に甘くなり、confidence は高止まりしやすい
ただし、ここで重要なのは 数式をいじらないことです。
やるのはあくまで
- 市場ごとに「現実の更新ギャップ(p95など)」を測り
- その現実に合わせて
stale_after_msを合わせる
という調整です。
今回あなたがやった「gap_p95 から逆算して stale_after を決める」方式は、
この数式と完全に整合しているので、設計として非常に綺麗です。
5) まとめ:confidence は “信号” ではなく “前提条件”
ここが重要なので、はっきり書きます。
signal_confidence は「方向」や「期待値」を作るための指標ではありません。
それは 前提条件(ゲート) です。
- 方向(Signal Code)や強さ(Strength)が出ても
- confidence が低いなら「採用しない」のが妥当
この分離ができると、
戦略ロジックは「条件が揃ったときだけ」歪みを解釈するようになります。
観測機を戦略に接続するうえで、signal_confidence はその土台になります。
Ⅵ. WSとHTTPで異なる健全性評価軸
今回の再設計で改めて実感したのは、
WS(WebSocket)とHTTPポーリングは、健全性の評価軸が根本的に違うという点でした。
同じ「データ取得」でも、前提が違えば異常の定義も変わります。
1) HTTPポーリング世界の健全性
HTTPポーリングは「周期的に取りにいく」モデルです。
- 0.6秒ごと
- 0.75秒ごと
- 5秒ごと
といった、期待周期が明確に存在する世界です。
この世界で重要なのは、
- tick_gap(前回取得からの経過時間)
- drop_rate(期待回数に対する欠損率)
- timeout(一定時間取得不能)
です。
ここでは、
“来ない” こと自体が異常
になります。
ポーリングでは「無音」は明確な故障です。
したがって、時間間隔ベースの評価が自然です。
2) WS(WebSocket)世界の健全性
一方、WSはイベント駆動です。
更新は「値が変わったとき」や「イベントが発生したとき」に飛んできます。
周期は保証されません。
つまり、
“来ない時間がある” ことは必ずしも異常ではない。
価格が動いていない時間帯でイベントが来ないのは、正常な挙動です。
そのため、HTTPと同じ drop_rate や期待回数ベースの評価を適用すると、意味が崩れます。
WS世界で重要なのは、
- heartbeat が維持されているか
- seq が単調増加しているか
- out_of_order が発生していないか
- recv_lag が異常に大きくなっていないか
- tick_gap が「想定外」に長くなっていないか
といった、イベント品質ベースの評価です。
3) drop_rate をWS市場から外した理由
もともと drop_rate はポーリング前提の指標でした。
しかし、WS化が進むにつれ、
- 期待回数という概念が曖昧になる
- イベント頻度が市場ごとに大きく異なる
- “価格が動かない”ことと“データが欠損している”ことが区別できない
という問題が出ました。
その結果、WS市場では drop_rate を健全性判定から外し、
- tick_gap
- stale
- latency_max
を中心としたゲートに切り替えました。
これは指標を減らしたのではなく、
意味を持つ軸だけを残したということです。
4) 同じ “stale” でも意味が違う
HTTPでは、
- 最終取得からの経過時間
が stale の意味になります。
WSでは、
- 最終イベント受信からの経過時間
- あるいは価格変化からの経過時間
になります。
さらに、
- イベントは来ているが価格が変わらない
- イベント自体が止まっている
は別問題です。
ここを区別しないと、
- 正常な静止状態を異常扱いする
- 異常な停止を見逃す
のどちらかになります。
5) 設計としての結論
WSとHTTPを同じ評価軸で扱うと、必ず歪みます。
そこで今回、
- HTTP市場は時間間隔ベースの健全性評価
- WS市場はイベント品質ベースの健全性評価
に分離しました。
評価軸を分けたことで、
- 不要な黄化
- 意味のない緑化
- 過剰な警戒
が減り、ダッシュボードの解釈が安定しました。
まとめ
健全性評価は「何を取得しているか」ではなく、
「どう取得しているか」に依存します。
WSとHTTPでは、世界が違う。
この前提を明確にしたことが、
multi_market_probe_v1 を戦略接続可能な観測基盤へ一歩進めた理由でした。
Ⅶ. stale_after_sec の市場別チューニング
signal_confidence の式を決めたあと、次に問題になったのはstale_after_sec をどう設定するかでした。
confidence は次の式で定義しています。
freshness = 1.0 - (max(base_stale_ms, ref_stale_ms) / stale_after_ms)
signal_confidence = clip(freshness, 0.0, 1.0)
この式では、stale_after_ms がそのまま 信頼度のスケール になります。
短くすれば厳しくなり、
長くすれば甘くなる。
つまり、stale_after_sec は単なる閾値ではなく、
「その市場をどれくらいの時間幅で“新鮮”とみなすか」
を決めるパラメータです。
1. 市場ごとに更新特性が違う
multi_market_probe_v1 では、各市場の更新頻度が大きく異なります。
直近30分の実測(価格変化ギャップ p95)は次の通りでした。
- bf_fx: 1.20s
- bf_spot: 2.23s
- binance_perp: 1.25s
- bybit_perp: 5.02s
- coinbase_spot: 3.77s
この時点で明らかなのは、
すべての市場に同じ stale_after_sec を適用するのは不合理
だということです。
bybit の p95 が 5秒を超えているのに、
stale_after_sec を 3秒にしていれば、
通常状態でも confidence が潰れてしまいます。
逆に、bf_fx に 10秒を与えれば、
鮮度低下が見えなくなります。
2. 数式から逆算する
confidence は
confidence = 1 - gap / stale_after
なので、ある目標 confidence を保ちたいなら、
stale_after >= gap_p95 / (1 - target_confidence)
で逆算できます。
例えば、
- p95 confidence ≥ 0.5 を目標にすると
- bybit は 10秒以上必要
- p95 confidence ≥ 0.3 なら
- bybit は 7秒程度で足りる
この逆算により、感覚ではなく数値で調整できるようになりました。
3. 実務バランスでの設定
理論的に最適な値と、実運用での扱いやすさは必ずしも一致しません。
最終的に採用した値は次の通りです。
- bf_fx: 2.0s(据え置き)
- bf_spot: 4.0s(+1.5s)
- binance_perp: 3.0s(据え置き)
- bybit_perp: 6.0s(+3.0s)
- coinbase_spot: 5.5s(+1.5s)
ここでの判断基準は、
- 平常時に confidence が潰れすぎないこと
- 異常時には確実に落ちること
- 数値として直感的に理解できること
です。
完璧な理論値を追うよりも、
「読める挙動」を優先しました。
4. チューニングの注意点
stale_after_sec をいじると、confidence の分布が一気に変わります。
そのため、以下をセットで見るようにしました。
- 市場別 signal_confidence の p50 / p95
- stale_ms の分布
- change_rate(価格変化率)
p50 だけを合わせると、
p95 で急落することがあります。
逆に甘くしすぎると、
異常が見えなくなります。
重要なのは、通常時に潰れないが、劣化時に明確に落ちることです。
5. なぜ市場別に持つのか
このチューニングを通じて見えてきたのは、
stale_after_sec は“戦略の思想”を反映するパラメータである
ということです。
高速更新市場では鮮度に厳しく、
更新の粗い市場では適度に緩くする。
これは「甘くする」ことではなく、
市場の特性に合わせて意味を揃えることです。
まとめ
stale_after_sec の市場別チューニングは、
- confidence を読みやすくし
- 平常時のノイズを減らし
- 異常時の変化を明確にする
ための作業でした。
単なる閾値調整ではなく、
観測値を“解釈可能なスケール”に合わせる工程です。
この調整によって、
multi_market_probe_v1 の数値はようやく「読める」形になりました。
Ⅷ. latency_max_ms_max の再設定と理由
stale_after_sec を市場別に調整したあと、次に手を入れたのがlatency_max_ms_max です。
もともとの設定は 6000ms でした。
これは「よほどのことがない限り DEGRADED にしない」保守的な値です。
観測専用フェーズでは合理的な初期値でした。
しかし、WS 化が進み、一次情報の整合性が確認できた段階で、この値は少し甘いと判断しました。
1. p95 では隠れるスパイク問題
ダッシュボードには Latency p95 を出しています。
p95 は平常状態の代表値を見るには便利ですが、
瞬間的なスパイクを隠す性質があります。
例えば、
- ほとんどが 150ms 前後
- たまに 4000ms を超えるスパイク
という状態でも、p95 はほとんど動きません。
しかし、実際のトレード判断においては、
その一瞬の遅延が歪みの誤認につながる
可能性があります。
そこで、p95 とは別にlatency_max_ms_max を品質ゲートとして使っています。
2. 6000ms は広すぎた
6000ms(6秒)は、
- ネットワーク断や
- API 詰まり
を検出するには機能しますが、
「悪化の予兆」を拾うには広すぎます。
今回の観測では、
- bf_fx / bybit / coinbase は 100〜200ms 台
- binance は遅延測定不能(unknown扱い)
といった水準でした。
この状態で 6000ms は、
実質的に“何も見ていない”に近い
と判断しました。
3. 4000ms への引き締め
そこで、段階的に
latency_max_ms_max: 6000 → 4000ms
へ引き締めることにしました。
いきなり 2000ms や 1500ms へ下げない理由は単純です。
- WS 再接続直後
- 一時的なネットワーク揺らぎ
- GC や一瞬の CPU スパイク
などで、瞬間的に跳ねることは現実的に起こり得ます。
まずは 4000ms に下げ、
- 30〜60分安定観測
- max 超過の回数や継続時間の確認
を行ったうえで、さらに引き締めるかを判断します。
4. 白黒判定としての役割
latency_max_ms_max は confidence とは違います。
confidence は連続値です。
latency_max は 白黒の品質ゲート です。
- 超えたら DEGRADED
- 超えなければ LIVE
という役割を持ちます。
この分離により、
- 平常時の信頼度評価(confidence)
- 構造的な健全性判定(health)
が明確に切り分けられます。
5. なぜ今この調整をするのか
観測基盤のフェーズでは、
- まず動くこと
- 次に整合性を確認すること
- 最後に品質を引き締めること
の順で進めるのが安全です。
いまは
- WS化完了
- raw証明済み
- stale_after 調整済み
という段階に入ったため、
ようやく latency の閾値を引き締められる状態になりました。
まとめ
latency_max_ms_max の再設定は、
- 観測が止まっているかどうかを見る段階から、
- 観測品質を一段引き上げる段階へ
進んだことを意味します。
過剰に厳しくするのではなく、
現実の挙動に合わせて段階的に締める。
それが今回の再設定の方針です。
Ⅸ. 現在の multi_market_probe_v1 の状態
ここまでの再設計を経て、multi_market_probe_v1 は「動いている観測機」から「戦略に接続可能な基盤」へと段階を進めました。
現時点の状態を、事実ベースで整理します。
1. 一次情報経路は確定している
各市場について、
- どのソース(WS / HTTP)から取得しているか
- payload のどのフィールドを bid / ask / ts / seq に変換しているか
- ts_exchange / ts_recv / recv_lag_ms をどう扱っているか
- 同値連打の扱い(quote_change_flag)
が明確になっています。
10秒間の raw ログ追跡により、
- 更新が止まっていないこと
- seq が逆行していないこと
- recv_lag が測れる市場では常識的な範囲であること
を確認済みです。
観測の入り口は、少なくとも壊れていません。
2. WS と HTTP の健全性評価が分離されている
ポーリング前提の drop_rate を WS 市場から外し、
- tick_gap
- stale
- latency_max
を中心とした品質ゲートへ移行しました。
また、遅延が測定不能な市場には latency_unknown_cap を適用し、
未知を良好扱いしない
という設計を固定しています。
評価軸の混在は解消されました。
3. signal_confidence は解釈可能なスケールに整った
stale_after_sec を市場別にチューニングしたことで、
- 平常時に confidence が不自然に潰れない
- 異常時には明確に低下する
という挙動が確認できています。
confidence は「方向を決める値」ではなく、
シグナルを採用する前提条件
として機能する状態になりました。
4. Health と Signal が明確に分離された
現在のダッシュボードは
[Q] → [E] → [M] → [S]
の順で読む設計に固定されています。
- [Q] が崩れた場合、[S] は無効
- [E] に異常がある場合、[M] は信用しない
- [M] が安定して初めて [S] を解釈する
この読み順が機能していることで、
「全部緑だけど不安」という状態は減りました。
5. まだ未完成な部分
もちろん、完成ではありません。
- Binance の exchange_ts 欠落問題
- latency_unknown の扱いの最適化
- premium 状態の定義の削減
- 実行系との接続時の安全設計
など、次の課題は残っています。
しかし、いまは「観測の土台」が安定した状態です。
まとめ
現在の multi_market_probe_v1 は、
- 一次情報の整合性が確認済み
- 健全性評価軸が整理済み
- confidence の意味が固定済み
- ダッシュボードの読解順が確立済み
という段階にあります。
観測機はプロトタイプから脱し、
戦略定義に進める状態になりました。
ここから先は、メトリクスを増やすのではなく、
何を“歪み”と呼ぶのか
を削っていくフェーズに入ります。
Ⅹ. 次フェーズ:歪み定義の削減
観測基盤の整理が一段落したいま、次にやるべきことは明確です。
メトリクスを増やすことではありません。
歪みの定義を削ることです。
1. 歪みは増やすほど強くなるわけではない
multi_market_probe_v1 には、すでに多くの状態量があります。
- edge_net
- ev_positive
- distortion_flag
- premium_regime
- premium_slope
- fx_dependency
- signal_ready
- signal_confidence
理論上は、これらを組み合わせればいくらでも高度な判定が作れます。
しかし、それをやると次の問題が起きます。
- 条件が増える
- 状態遷移が複雑になる
- なぜエントリーしたのか説明できなくなる
歪みの定義が増えるほど、戦略は強くなるのではなく、
不透明になります。
2. 「観測可能」と「戦略可能」は違う
ここまでで、
- 他市場の更新状況
- 鮮度
- 遅延
- premium の背景
- EV の符号
は観測可能になりました。
しかし、それはあくまで材料が揃っただけです。
次の問いはこれです。
どの歪みだけを戦略に採用するのか。
すべてを使う必要はありません。
むしろ、使わないものを決めることの方が重要です。
3. 削るとは、前提を固定すること
歪み定義を削るとは、
- 使う状態量を限定する
- 無視する状態量を明示する
- 解釈の順序を固定する
ことです。
例えば、
- premium_regime を条件に入れるのか
- fx_dependency を強制ゲートにするのか
- signal_confidence の下限をどこに置くのか
これらを増やし続けるのではなく、
まずは 最小構成で通す。
4. 現在の土台でできること
いまの multi_market_probe_v1 では、
- 健全性は白黒で判定できる
- 鮮度は連続値で扱える
- edge_net は同単位で比較できる
- premium の背景も観測できる
この状態で、まずは
edge_net > 0
かつ
signal_confidence >= X
という単純な定義から始めてもよいはずです。
そこに regime や slope を積み増すのは、その後でも遅くありません。
5. 次フェーズの方針
次のフェーズでは、
- 「歪み」の定義を 1〜2 個に絞る
- 条件を増やさない
- 解釈できる状態を維持する
ことを優先します。
観測基盤は整いました。
ここからは、
何を歪みと呼び、何を無視するか
を決めるフェーズです。
削ることで、戦略は初めて前に進みます。